Arrays and Linked Lists
2020-02-17T23:46:37.491ZArrays and Linked Lists
Sources:
- Introduction to Java Programming by Y. Daniel Liang
- Grokking Algorithms by Aditya Bhargava
- Algorithms & Data Structures by Stephen Grider
- The Ultimate Data Structures & Algorithms Series by Mosh Hamedani
- Programming Interviews Exposed by John Mongan et al.
- Common-Sense Guide to Data Structures and Algorithms by Jay Wengrow
Whenever you want to store an item in memory, you ask for some space and receive an address in memory to store your item at. To store multiple items in a series, there are two options: arrays and lists.
In an array, all items are stored contiguously (right next to each other). The problem is that, if you need to store more items than the array has space for, you need to:
- create a whole new array in a new chunk of memory to store the added items, with the obvious downsides, or
- you need to create a bigger sized array to begin with, with the downside of wasting unused space and the potential, or eventually reaching the limit and having to create a whole new array anyway.
The worst-case scenario for insertion into an array is where we insert data at the beginning of the array, because when inserting into the beginning of the array, we have to move all the other values one cell to the right. Insertion in a worst-case scenario can take up to n + 1 steps for an array containing n items. This is because the worst-case scenario is inserting a value into the beginning of the array in which there are n shifts and one insertion.
Deletion is like insertion but in reverse. So we’ve just seen that when it comes to deletion, the deletion is just one step, but we need to follow up with additional steps of shifting data to the left to close the gap caused by the deletion. Like insertion, the worst-case scenario of deleting an element is deleting the very first element of the array. This is because index 0 would be empty, which is not allowed for arrays, and we would have to shift all the remaining elements to the left to fill the gap.
In sum, arrays are slow at insertion, but fast at reading random elements via indexing, because you know the address of every item and can look up any element in your array instantly. (The computer can jump to any index within the set since it knows the memory address that the set begins at.) A lot of use cases require random access, so arrays are used a lot.
Aside: Set
A set is an array with one simple constraint: no duplicates. Because of this constraint, the set has a different efficiency for one of the four primary operations. Insertion is where arrays and sets diverge.
Inserting a value at the end of a set was a best-case scenario for an array. With an array, the computer can insert a value at its end in a single step. With a set, however, the computer first needs to determine that this value does not already exist in this set, to prevent duplicates. Every insert first requires a search. Insertion into a set in a best-case scenario will take n + 1 steps for n elements. This is because there are n search steps to ensure that the value does not already exist within the set, and then one step for the actual insertion. In a worst-case scenario, where we are inserting a value at the start of a set, the computer needs to search n items to ensure that the set does not already contain that value, and then another n steps to shift all the data to the right, and another final step to insert the new value, for a total of 2n + 1 steps.
Aside: Ordered array
In an ordered array, whenever a value is added, it is placed in the proper item so that the values of the array remain ordered. In a regular array, values can be added to the end of the array regardless of the order of the items. Therefore, when inserting into an ordered array, we need to always conduct a search before the actual insertion, so as to determine the location for the insertion. Ordered arrays are slower than regular arrays at insertion. However, the ordered array is faster at search: the ordered array allows for binary search. Binary search is impossible with a standard array because the values can be in any order. In short, insertion in ordered arrays is slower than in regular arrays, but by using an ordered array, you have somewhat slower insertion, but much faster search.
Back to linked lists
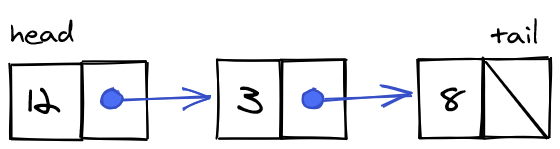
In a linked list, the items can be anywhere in memory—each item stores the address of the next item, and so random memory addresses are linked together. Each node contains data and a reference to the next node. The order is fixed. The first node is the head and the last node is the tail. The tail usually has next: null.
In other words, linked lists consist of a group of memory cells (called "nodes") that are not next to each other, but can be spread across many different cells across memory. Each node stores its value and also the memory address of the next node in the linked list. Since each node contains a link to the next node, if we identify the first node of the linked list, the computer can piece together the rest of the list by following the link of the first node to the second node, and the link from the second node to the third node, and so on. One advantage of a linked list over an array is that the program does not need to find a group of empty memory cells in a row to store its data. Instead, the computer can store the data across cells that are not necessarily adjacent to each other.
Linked lists are slow at reading. The items are not contiguous in memory, so you cannot instantly calculate the position of the nth item—you have to go to the first item to get the address to the second, then go to the second to get the address of the third, and so on until you get to the nth item. In other words, linked lists can only do sequential access. If you want to read the 10th element of a linked list, you are required to read the first 9 elements, following the links up to the 10th element.
The value at index 2 of a linked list cannot be looked up in one step, because it the computer cannot immediately know where to find it in memory. Each node of a linked list may be anywhere in memory. The computer only immediately knows the memory address of the first node of the linked list. To find index 2 (which is the third node), the computer must look up index 0 of the linked list, and then follow the link at index 0 to index 1, and from there to index 2.
On the other hand, linked lists are better than arrays at insertion. If you remember, the worst-case scenario for insertion into an array is when the program inserts data into index 0, because it then has to shift the rest of the data one cell to the right, which ends up yielding an efficiency of O(n). With linked lists, however, insertion at the beginning of the list takes just one step, that is, O(1).
Arrays vs. linked lists
Arrays are great for reading (index access). Linked lists are great for mutation (item insertion). The calculation of the memory address of the item in an array is O(1). Access by index is fast: O(1). To exapand an array to accommodate more items, the runtime complexity is O(n) → the runtime cost of the operation increases linearly, in direct proportion to the size of the array.
What about deletion? Again, lists are better, because you just need to change what the previous element points to. With arrays, everything after the deleted element needs to be shifted leftwise when you delete an element. In an array, deletion from the right is simple and fast, but deletion from the left means shifting all items to the right.
| Operation | Array | Linked list |
|---|---|---|
| reading by index | O(1) |
O(n) |
| reading by value | O(n) |
O(n) |
| insertion at start/end | O(n) |
O(1) |
| insertion at middle | O(n) |
O(n) |
| deletion at start | O(n) |
O(1) |
| deletion at end | O(n) |
O(n) |
| deletion at middle | O(n) |
O(n) |
Space complexity: Static arrays have a fixed size. Static arrays grow by 50% to 100% and may end up wasting memory; linked lists take up only as much memory as they need.
Runtime complexity: Arrays shine when you need to look up a value by an index; in linked lists, you have to traverse until you find the value at a given index. Whenever you need to traverse the nodes in a linked list, your operation becomes O(n).
In Python and JavaScript, arrays are dynamic, i.e., they can grow automatically to fit in more items. In Java, Array is static, i.e. size is fixed at creation, but ArrayList is dynamic. For lists that grow and shrink automatically, use linked lists.
Array in Java:
public class Main {
public static void main(String[] args) {
int[] numbers = { 10, 20, 30 }; // size of 3, items are 10, 20, 30
}
}
Linked list in Java:
public class Main {
public static void main(String[] args) {
LinkedList<Integer> linkedList = new LinkedList();
}
}
Background
An array is a sequence of variables of the same type arranged contiguously in a block of memory.
Like a linked list, an array provides an essentially linear form of storage, but its properties are significantly different. (Multidimensional arrays are not exactly linear, but they are implemented as linear arrays of linear arrays.) In a linked list, lookup is always an O(n) operation, but array lookup is O(1) as long as you know the index of the element you want. The provision regarding the index is important—if you know only the value, lookup is still O(n) in the average case. For example, suppose you have an array of characters. Locating the sixth character is O(1), but locating the character with value w is O(n).
The price for the array's improved lookup is significantly decreased efficiency for insertion and deletion of data in the middle of the array. Because an array is essentially a block of contiguous memory, it's not possible to create or eliminate storage between any two elements as it is with a linked list. Instead, you must physically move data within the array to make room for an insertion or to close the gap left by a deletion; this is an O(n) operation.
Arrays are static data structures: they have a finite, fixed number of elements. Memory must be allocated for every element in an array, even if only part of the array is used. Arrays are best used when you know how many elements you need to store before the program executes. When the program needs a variable amount of storage, the size of the array imposes an arbitrary limit on the amount of data that can be stored. Making the array large enough so that the program always operates below the limit doesn't solve the problem: either you waste memory or you won't have enough memory to handle the largest data sizes possible.
Most modern languages also have library support for dynamic arrays: arrays that can change size to store as much or as little data as necessary. (Some languages, typically scripting languages, use dynamic arrays as their fundamental array type and have no static array type.) Most dynamic array implementations use static arrays internally. A static array cannot be resized, so dynamic arrays are resized by allocating a new array of the appropriate size, copying every element from the old array into the new array, and freeing the old array. This is an expensive operation that should be done as infrequently as possible.
A Java array is an object in and of itself, separate from the data type it holds. A reference to an array is therefore not interchangeable with a reference to an element of the array. Java arrays are static, and the language tracks the size of each array, which you can access via the implicit length data member.
Arrays in JavaScript are instances of the Array object. JavaScript arrays are dynamic and resize themselves automatically.
Implementation
Implementing a dynamic array in Java:
public class Array {
private int[] items;
private int count;
public Array(int length) {
items = new int[length];
}
public void print() {
for (int i = 0; i < count; i++) {
System.out.println(items[i]);
}
}
public void insert(int item) {
if (items.length == count) {
int[] newItems = new int[count * 2];
for (int i = 0; i < count; i++) {
newItems[i] = items[i],
}
items = newItems;
}
items[count] = item;
count++;
}
public void removeAt(int index) {
if (index < 0 || index >= count) {
throw new IllegalArgumentException();
}
for (int i = index; i < count; i++) {
items[i] = items[i + 1];
}
count--;
}
public int indexOf(int item) {
for (int i = 0; i < count; i++) {
if (items[i] == item) {
return i;
}
return -1;
}
}
}
Implementing a linked list in Java:
public class LinkedList {
private class Node {
private int value;
private Node next;
public Node(int value) {
this.value = value;
}
}
private Node first;
private Node last;
private int size;
public void addLast(int item) {
Node node = new Node(item);
if (first == null) {
first = node;
last = node;
} else {
last.next = node;
last = node;
}
size++;
}
public void addFirst(int item) {
Node node = new Node(item);
if (first == null) {
first = node;
last = node;
} else {
node.next = first;
first = node;
}
size++;
}
public void indexOf(int item) {
int index = 0;
var current = first; // current node
while (current != null) {
if (current.value == item) return index;
current = current.next;
index++;
}
return -1;
}
public boolean contains(int item) {
return indexOf(item) != -1;
}
public void removeFirst() {
// no items in list
if (first == null) {
throw new NoSuchElementException();
}
// single item in list
if (first == last) {
first = null;
second = null;
return;
} else {
var second = first.next;
first.next = null;
first = second;
}
size--;
}
public void removeLast() {
if (first == null) {
throw new NoSuchElementException();
}
if (first == last) {
first = null;
last = null;
return;
} else {
var previous = getPrevious(last);
last = previous; // list is shrunk
last.next = null; // removes link to previously last node
}
size--;
}
private Node getPrevious(Node node) {
var current = first;
while (current != null) {
if (current.next == node) return current;
current = current.next;
}
return null;
}
public int size() {
return size;
}
public int[] toArray() {
int[] array = new int[size];
var current = first;
int index = 0;
while (current != null) {
array[index] = current.value;
index++;
current = current.next;
}
return array;
}
}
Implementing a linked list in JavaScript:
class Node {
constructor(data, next = null) {
this.data = data;
this.next = next;
}
}
class LinkedList {
constructor() {
head = null;
}
insertFirst(data) {
// create a new node
// set it to refer to original head
// set head to new node
// before: ON (OH)
// after: NN (NH) → ON (OH)
this.head = new Node(data, this.head);
}
size() {
let counter = 0;
let node = this.head;
while (node) {
counter++;
node = node.next;
}
return counter;
}
getFirst() {
return this.head;
}
getlast() {
let node = this.head;
if (!node) return null;
while (node) {
if (!node.next) return node;
node = node.next;
}
}
clear() {
this.head = null;
}
removeFirst() {
if (!this.head) return;
this.head = this.head.next;
}
removeLast() {
if (!this.head) return;
if (!this.head.next) {
this.head = null;
return;
}
let previous = this.head;
let node = this.head.next;
while (node.next) {
previous = node;
node = node.next;
}
previous.next = null;
}
insertLast(data) {
let last = this.getLast();
if (!last) {
this.head = new Node(data);
}
last.next = new Node(data);
}
getAt(index) {
let node = this.head;
let counter = 0;
while (node) {
if (counter === index) return node;
counter++;
node = node.next;
}
return -1;
}
removeAt(index) {
if (!this.head) return;
if (index === 0) {
this.head = this.head.next;
}
const previous = getAt(index - 1);
if (!previous || !previous.next) return;
previous.next = previous.next.next;
}
insertAt(data, index) {
if (!this.head) {
this.head = new Node(data);
return;
}
if (index === 0) {
// create new node
// point it to current head
// assign new node to be the new head
this.head = new Node(data, this.head);
return;
}
const previous = this.getAt(index - 1) || this.getLast();
const nodeBeingInserted = new Node(data, previous.next);
previous.next = nodeBeingInserted;
}
forEach(fn) {
let node = this.head;
let counter = 0;
while (node) {
fn(node, counter);
node = node.next;
counter++;
}
}
}
Types of linked lists
- Singly: Each node has a reference/pointer to the next node.
- Doubly: Each node has a reference/pointer to the previous and next node.
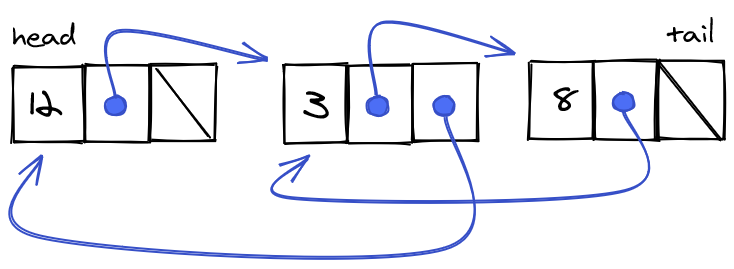
A singly linked list has O(n) for deletion at end (poor), but only needs one node pointer (next) and so takes up less space. Each data element in the list has a link (a pointer or reference) to the element that follows it in the list, as shown in Figure 5-1. The first element in a singly linked list is referred to as the head of the list. The last element in such a list is called the tail of the list and has an empty or null link.
Because the links in a singly linked list consist only of next pointers (or references), the list can be traversed only in the forward direction.
A doubly linked list has O(1) for deletion at end (great), but needs two pointers (previous, next) and so takes up more space. In a doubly linked list, each element has a link to the previous element in the list as well as to the next element in the list. This additional link makes it possible to traverse the list in either direction. A doubly linked list has head and tail elements just like a singly linked list. The head of the list has an empty or null previous link, just as the tail of the list has a null or empty next link.
Both singly and doubly linked lists can be circular, i.e. the last node points to the first node. Circular linked lists have no ends—no head or tail. Each element in a circular linked list has non-null next (and previous, if it's also doubly linked) pointers or references.
Common operations with linked lists
Reversing a linked list:
// [10 → 20 → 30]
// p → c → n
private void reverse() {
if (first == null) return;
var previous = first;
var current = first.next;
while (current != null) {
var next = current.next;
current.next = previous;
previous = current;
current = next;
}
last = first;
last.next = null;
first = previous;
}
Finding the kᵗʰ node from the end in one pass:
public Node getKthFromTheEnd(int k) {
if (first == null)
throw new IllegalStateException();
var a = first; // this pointer is k apart from b ← solution
var b = first; // this pointer bumps into end
for (i = 0; i < k - 1; i++) { // k - 1 is separation
b = b.next; // advance second pointer to make it k apart from a
if (b == null) // meaning: k is greater that size of linked list
throw new IllegalArgumentException();
}
while (b != last) { // advance both until b is last
a = a.next;
b = b.next;
}
return a;
}