Firebase Basics
2019-11-14T23:46:37.744ZFirebase Basics
Firebase is a Backend-as-a-Service (BaaS) app development platform that provides hosted backend services such as a realtime database, cloud storage, authentication, crash reporting, machine learning, remote configuration, and hosting for your static files.
Setup
1. Create db
- Go to the Firebase console and
Add project - Select
Databasefrom the left nav andCreate database - Select starting mode for the db:
test mode
2. Populate db
- At Firebase Console,
Project Overview→+ Add app→Web - Make a note of
apiKey,authDomainandprojectId. - Use custom script:
json-to-firestore.jsatinfobotleg/data.
3. Connect db to Flutter app
- At Firebase Console,
Project Overview→+ Add app→Android. - Insert package name into wizard:
my.domain.myapp. - (Optional) If using
Google Sign In, insert the SHA-1 value of a debug signing certificate into wizard.
$ cd /c/Program Files (x86)/Java/jre1.8.0_111/bin
./keytool -list -v -alias androiddebugkey -keystore /c/Users/[user]/.android/debug.keystore
- Click
Register App. - Download
google-services.jsonplace it in theandroid/appdir. - Update your two gradle files (project-level and app-level gradle files) as per the wizard.
4. Add dependencies and import
Add two dependencies in pubspec.yaml:
dependencies:
firebase_core:
cloud_firestore:
firebase_auth: // only if the app will have auth
Import them into code:
import 'package:cloud_firestore/cloud_firestore.dart';
5. Debugging
In case of errors, try these solutions:
Go back to local project directory and replace all instances of com.example with your custom reverse domain. All instances barring none.
Fix application ID:
com.example.myapp // replace all instances
Fix kotlin version:
ext.kotlin_version = '1.3.0'
Fix gradle version:
classpath 'com.android.tools.build:gradle:3.3.2'
Fix SDK version:
minSdkVersion 21
Data modeling
Firestore stores collections (arrays) of documents (objects), which contain key-value pairs. Values may be subcollections (arrays of objects).
| NoSQL | SQL |
|---|---|
| collection | table |
| document | row |
| documentID | primary key |
| key | column |
| value | cell |
Rules
- Document: A document is like a JSON-object, minimal unit of storage in a NoSQL database. Every document must belong to a collection. A document may have field-value or field-subcollection. The value in field-value may be a string, int, boolean, array, map, etc. Document names within a collection must be unique. Each document has a 1 MB size limit.
- Collection. A collection is an array of documents. A subcollection (nested collection) is an array of documents that is the value of a field in a document. A subcollection is not part of the document, so it must be queried independently.
- Schemaless. A Firestore database is schemaless, so document fields may very among documents. At the top level of the database we only have collections.
- Retrieval. You may retrieve only documents, not collections or subcollections. You may not retrieve a partial document. Retrievals are shallow, so subcollections are not brought in.
- Differences from SQL. Relational databases are normalized: they try to break down the data into as many small parts as possible, to prevent data duplication. Also, there is no
JOINin Firestore. Joins are not CPU-efficient at scale. NoSQL designs data so that it does not require aJOIN.
Guidelines
- Aim for long collections of small documents. If a document becomes too large, nest data in a deeper collection.
- Store data vertically (collections and many subcollections) if you are mostly going to be searching for items per subcollection and only occasionally do a collection group query.
- Store data horizontally (many top-level collections) if you are mostly going to be searching across all documents and only occasionally do a per-item query.
- Put data in the same document (e.g. as in-doc top-level values, or in a map) if you are always going to display it together, e.g. fields in a dictionary entry.
- Put specific data in collections if you are going to want to search that specific data, and not its containing data, or so that it has room to grow.
Model data to fit the screen
Model your data based on how it will be consumed by the app. Your database design has to be the path of least resistance to get data from the db into a view.
Example
// collection, at db root
users
// document1
ada-lovelace
first : "Ada"
last : "Lovelace"
born : 1815
// document2
alan-turing
first : "Alan"
last : "Turing"
born : 1912
friends: // subcollection
// nested document
john-malkovich
first : "John"
second : "Malkovich"
born: 1950
Data locations
Data may be located inside:
- a document key-value pair (or in a map inside the value) (embedding),
- a top-level collection (root collection),
- a subcollection, or
- simultaneously in two top-level collections (bucketing).
Importing JSON
You can import JSON to Firestore. Use a key at the top of the JSON file as the name for the collection to be created at Firestore.
- https://levelup.gitconnected.com/firebase-import-json-to-firestore-ed6a4adc2b57
- https://stackoverflow.com/questions/46640981/how-to-import-csv-or-json-to-firebase-cloud-firestore
Firestore code snippets
References
Document reference:
let alovelaceDocumentRef = Firestore.instance.collection('users').doc('alovelace');
Collection reference:
let usersRef = Firestore.instance.collection('users');
Subcollection reference:
let roomAmessagesRef = Firestore.instance
.collection('rooms')
.doc('roomA')
.collection('messages')
Create
Create named document in collection:
Firestore.instance
.collection('my-collection')
.document('my-doc') // must be string
.setData({
'field1': 'some string',
'field2': 'some other string'
});
Firebase for JS uses .doc and .set!
Create autoID document in collection:
Firestore.instance
.collection('my-collection')
.add({
'field1': 'some string',
'field2': 'some other string'
});
Read
Retrieve all documents from collection:
const snapshot = await Firestore.instance
.collection('my-collection')
.getDocuments();
snapshot.documents.forEach((document) => {
print(document.data());
});
Retrieve single (named) document from collection:
Firestore.instance
.collection('my-collection')
.document('my-doc');
Update
Update (named) document in collection:
Firestore.instance
.collection('my-collection')
.document('my-doc')
.updateData({
'field1': 'some new string',
'field2': 'some other new string'
});
Delete
Delete (named) document in collection:
Firestore.instance
.collection('my-collection')
.document('my-doc')
.delete();
Exists
updateUser() async {
final doc = await usersRef.document('sdfljbasdfjbafds').get();
if (doc.exists) {
doc.reference.updateData({
// ...
});
}
}
Collection queries
Condition with where:
db.collection('posts').where('date', '==', today)
db.collection('posts').where('name', 'array-contains', 'john')
// chained `where` statements are equivalent to `AND` in SQL
Sort with orderBy:
db.collection('posts').orderBy('published', 'asc');
// NB: if post has no `published` field, it will be filtered out
Paginate with limit:
db.collection('posts').orderBy('published', 'asc').limit(10);
Paginate with startAt, startAfter, endAt, endBefore:
db.collection('posts').orderBy('published', 'asc').startAt(lastWeek);
db.collection('posts').orderBy('published', 'asc').startAfter(lastWeek);
db.collection('posts').orderBy('published', 'asc').endAt(lastWeek);
db.collection('posts').orderBy('published', 'asc').endBefore(lastWeek);
Subcollection queries
db.collectionGroup('books').where('published', '==', '1974');
Subcollection queries are also known as collection group queries.
A subcollection query is a query made across multiple subcollections, as long as the subcollection/property shares the same name.
Composite index
db.collection('posts')
.where('author', '==', 'bob')
.where('date', '>=', lastWeek);
A composite index is an index built for two or more fields of documents in a collection. A composite index is used for queries that have two or more where clauses looking at two or more properties.
Go to the Indices tab. Or you can write the code in your client-side app and an error will be thrown with a link to create the composite index.
Cardinality
Cardinality, a.k.a. data relationships:
- one-to-one
- one-to-many
- many-to-many
One-to-one relationship
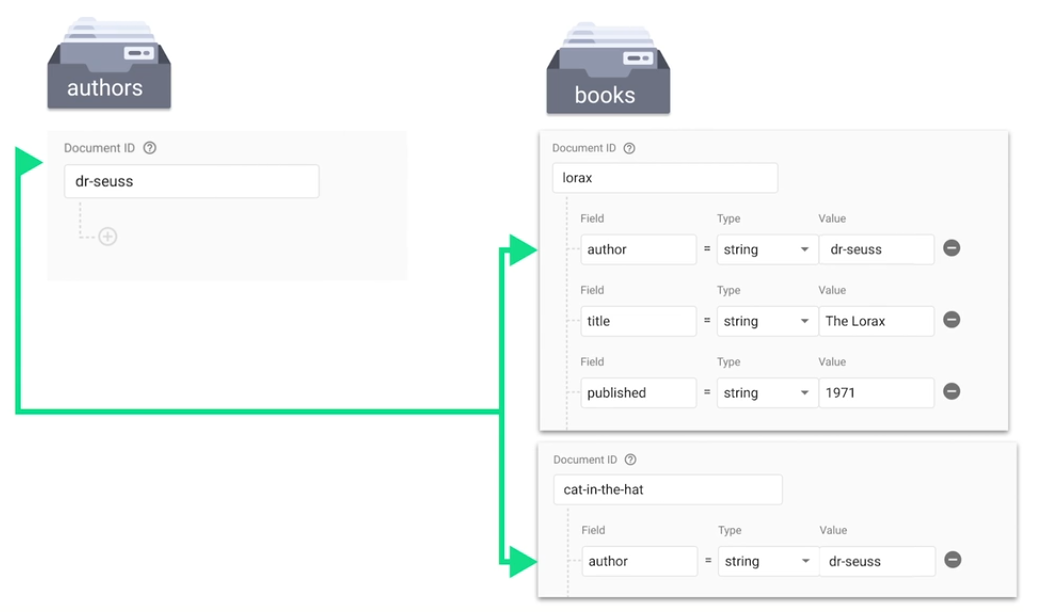
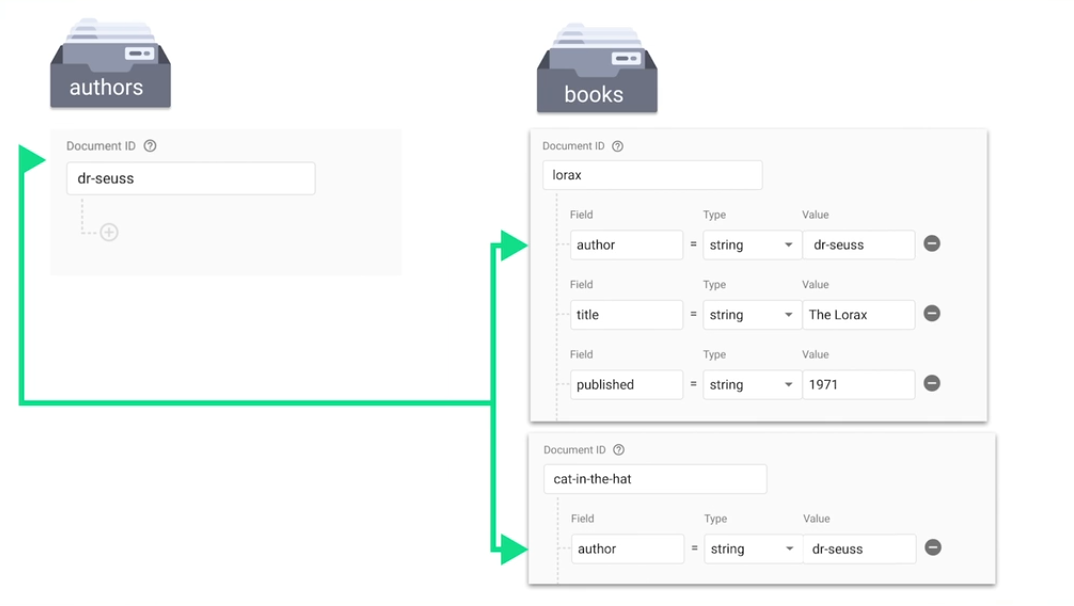
If you have an authors collection with individual documents for individual authors, you can simply have all the data for an author inside their document
However, if some of the data is sensitive, partition the data: create an authors-sensitive collection with individual documents for individual authors and move the sensitive data from the authors collection to the authors-sensitive collection. (Use exact same document IDs in both collections.)
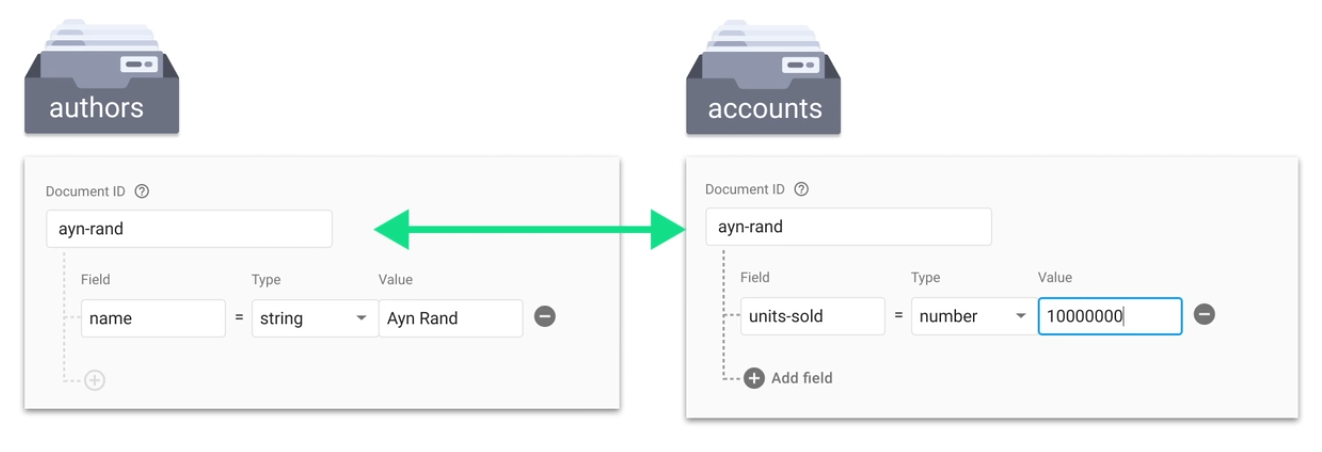
One-to-many relationship
One option is to embed an array of maps inside a value in the document.

If you need to query a subset of data inside the document, create in the document a subcollection containing the subset.

If you need to query the subsets across multiple other documents, use a root collection containing the subsets as documents.
Many-to-many relationship
Use an intermediate table (a.k.a. link table) as a middleman collection.
++usersCollection
userDoc
- username
- email
++starsCollection // middleman collection
starDoc
- userId
- movieId
- value
++moviesCollection
movieDoc
- title
- plot
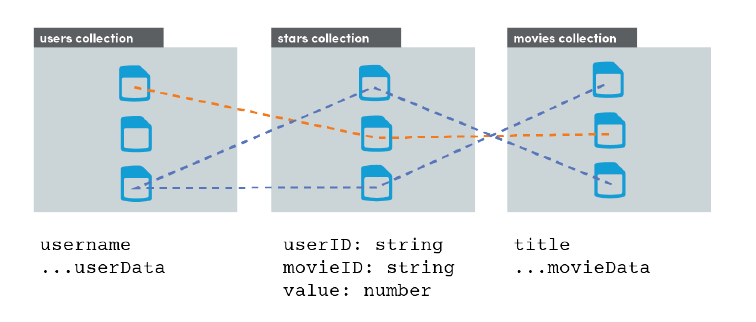
In the graphic above, we can see how the movies collection and users collection have a two-way connection through the middle-man stars collection. All data about a relationship is kept in the stars document - data never needs to change on the connected user/movie documents directly. This is similar to a many-to-many relationship in a SQL database.
Securing collections
If you have a collection with sensitive user data (e-mail, etc), then...
To secure the data from everyone:
match /userdata/{userId} {
allow read, write: if false;
}
To secure the data from everyone but its user owner:
match /userdata/{userId} {
allow read, write: if userId == request.auth.id;
}
Data manipulation
Data duplication
Data duplication reduces reads, so it makes sense for when your app requires many reads but few writes. This is often the normal use case, you read data much more often than you change it.
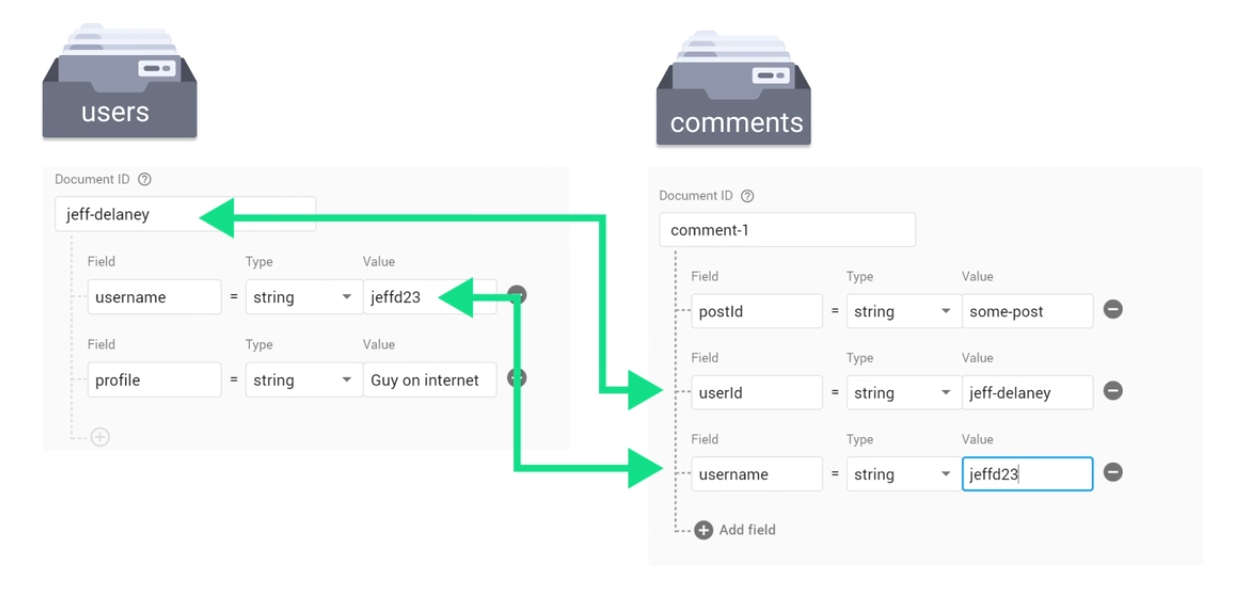
But if you have a value that will change frequently, avoid data duplication so that you avoid having to hunt down that value everywhere it exists in order to change it.
Data aggregation
Data aggregation is calculating a value based on a collection of documents. Use Cloud Functions.
Data model examples
Likes, hearts, upvotes
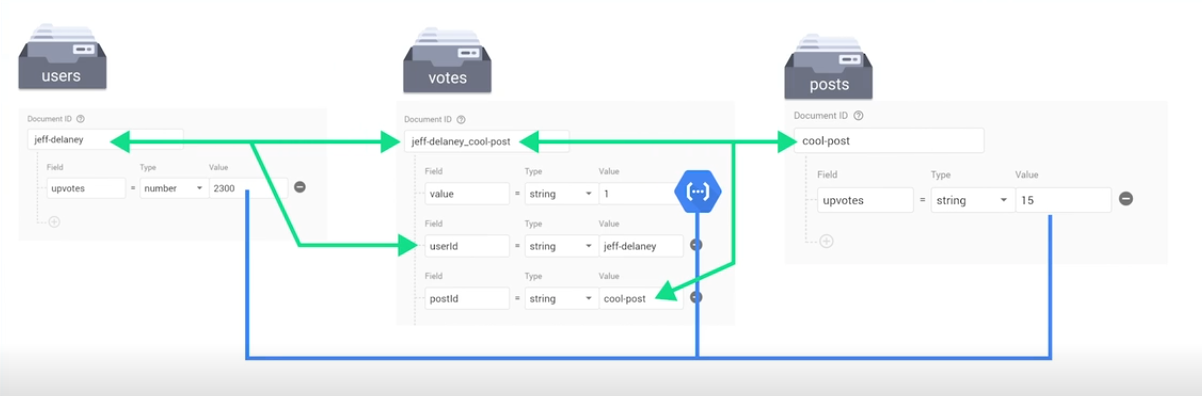
Pay attention to the name of each document in the votes collection. The name is a composite of user and post, so it enforces uniqueness, i.e., no user can vote on a post more than once.
Role-based authorization
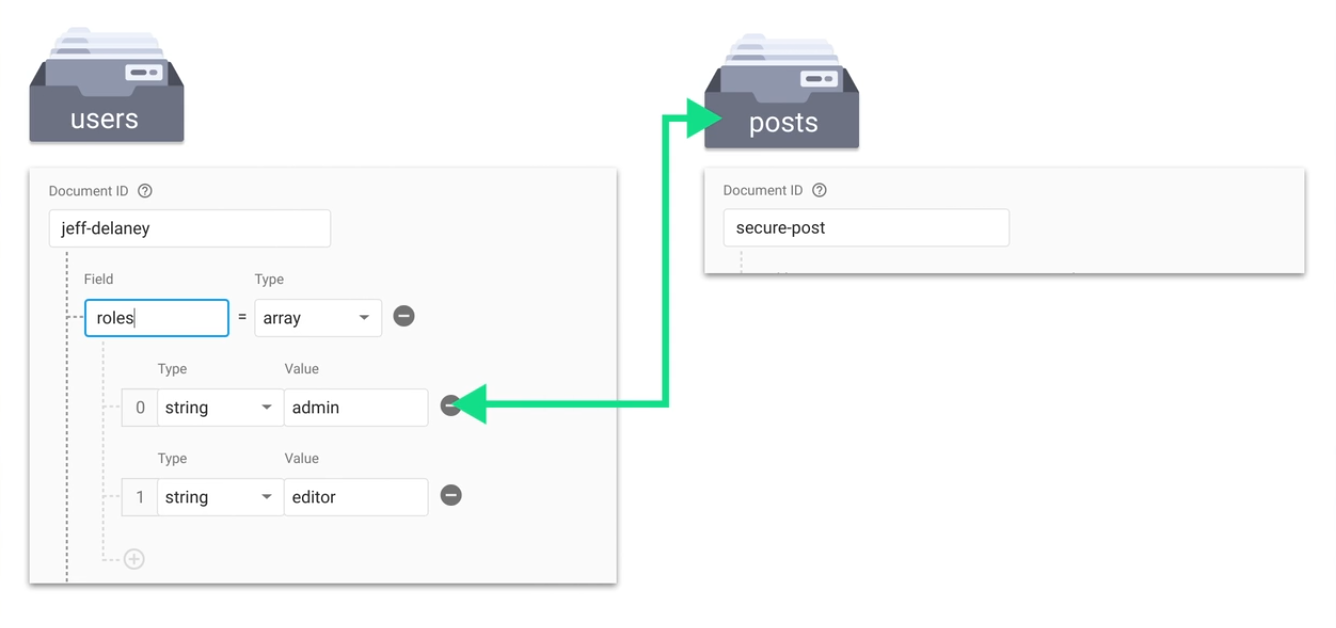
And then secure the posts collection:
match /posts/{post} {
function getRoles() {
return get(/databases/($database)/documents/users/$(request.auth.uid)).data.roles;
}
allow read;
allow write: if getRoles().hasAny(['editor', 'admin']);
}
One disadvantage here is that you are using get(), which consumes an additional document read.
Access control list
Make an access control list tied to an individual post, so you query the post to see if the user trying to access it is authorized to do so.
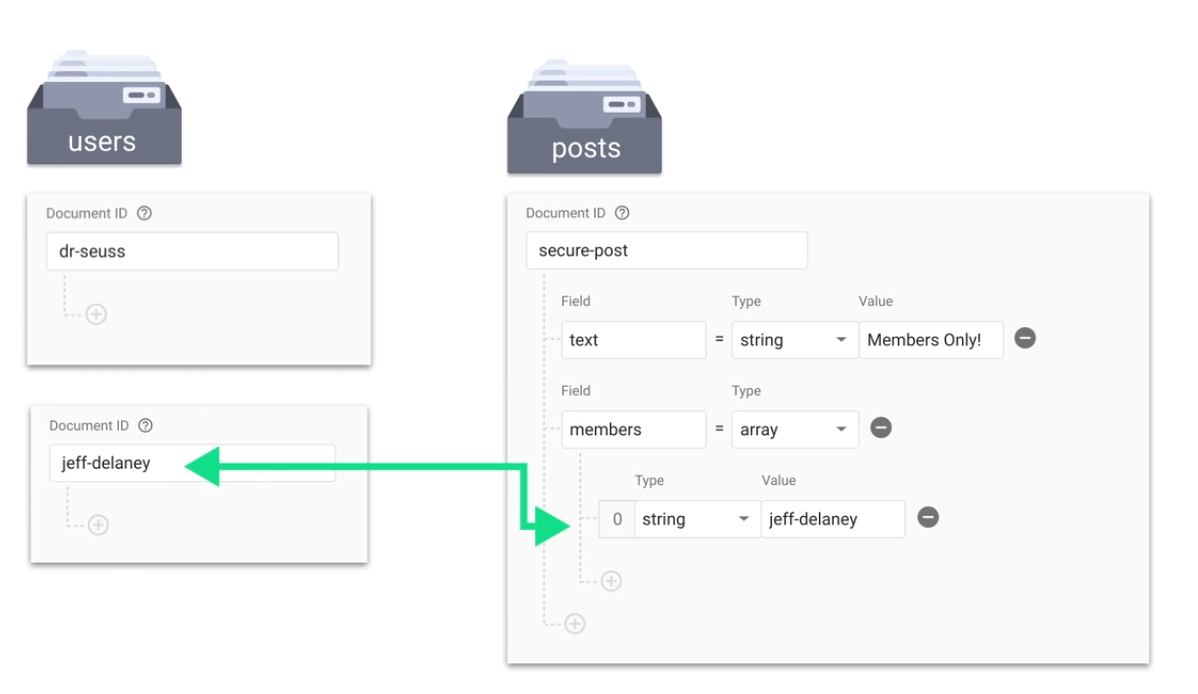
And then secure the posts collection:
match /posts/{post} {
allow read;
allow write: if resource.data.members.hasAny(request.auth.uid);
}
Save relational data in whichever entity has fewer relationships.
Billing
Billing is mostly based on the number of documents you read.
Set up a billing alert.
Use aggregate documents to reduce reads. (See database triggers.)
exports.aggregate = functions.firestore
.document("donations/{donationId}").onCreate(
async (snapshot, context) => {
const donation = snapshot.data()
const aggRef = db.collection("aggregation/donations");
const aggDoc = await aggRef.get();
const aggData = aggDoc.data();
}
const next = {
total: aggData.total + donation.amount,
count: aggData.count + 1,
last5: [donation, ...aggData.last5, slice(0, 4)]
}
return aggRef.set(next);
)