Designing a rate limiter
2023-07-04T09:02:32.541ZDesigning a rate limiter
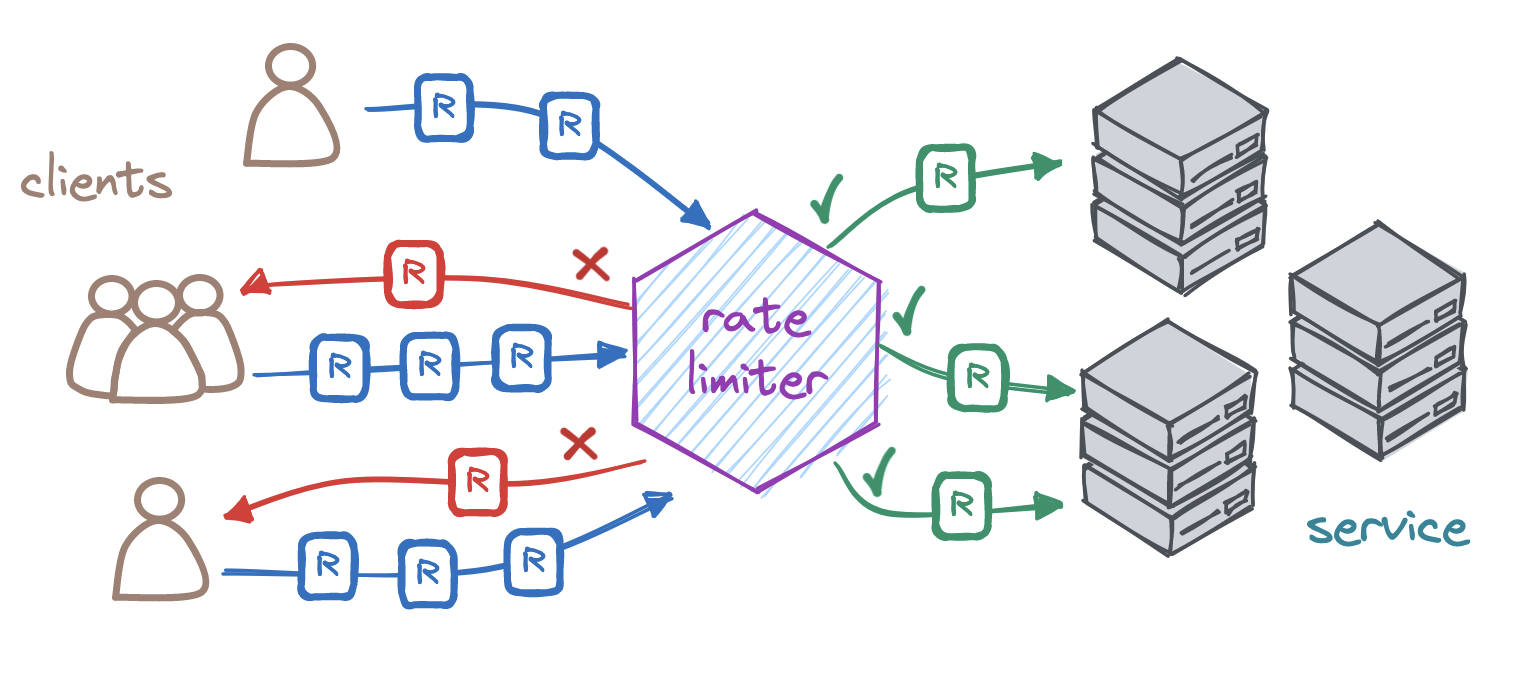
All production-grade services rely on rate limiters - when a user may post at most five articles per minute, or when an API responds at most 500 times an hour, or when a download is slowed down after some data is transferred, there is a rate limiter at work. Rate limiting restricts the flow of requests that a server will accept in a time window. Whenever a caller exceeds this limit within this period, the rate limiter denies any excess requests, preventing them from ever reaching our server.
Why is it useful to rate-limit?
-
Rate limiting prevents excessive use of our own resources. An overly high flow of requests may bring down our server. If we cannot scale up our system to serve all these requests, a rate limiter can save it from suffering a series of cascading failures. And if the high load is malicious, as in a denial-of-service attack, rate limiting serves as our first line of defense.
-
Rate limiting prevents excessive use of external resources. If we rely on a paid external service, then excessive usage may cause cost overruns - rate limiting safeguards against this. Likewise, if the external service is itself rate limited, which is very likely the case, then setting a rate limit on our end prevents us from we overstepping the third party's rate limit.
-
Rate limiting prevents excessive use of our users' resources. If we have a service that is used by multiple users, a rate limit ensures that no single user can monopolize our service. This way, we ensure that our service is fairly available to all our users, rather than only a few.
Let's look at the main factors to consider when designing a rate limiter.
Where to start?
To design a rate limiter, we should look at who our clients are, what our clients' expectations are, and what level of service we can offer. Specifically, we should look at the number of callers, average and peak number of requests per client, average size of incoming requests, likelihood of surges in traffic, max latency our callers can tolerate, and the throughput and latency our system can achieve.
Only then can we start defining a rate limiting policy:
- the number of requests and the unit of time,
- the max size of the incoming requests,
- which endpoints to rate limit,
- how to respond when rate limiting,
- how to react on rate limiter failure,
- where to locate the rate limiter,
- where to store rate-limiting state,
- whether to limit per account or per IP or otherwise,
- whether to also institute a global rate limit,
- whether specific endpoints should be limited differently,
- whether groups of clients should be limited differently,
- whether to limit strictly or allow bursts of requests, and
- which rate-limiting algorithm to use.
Let's unpack some of these aspects.
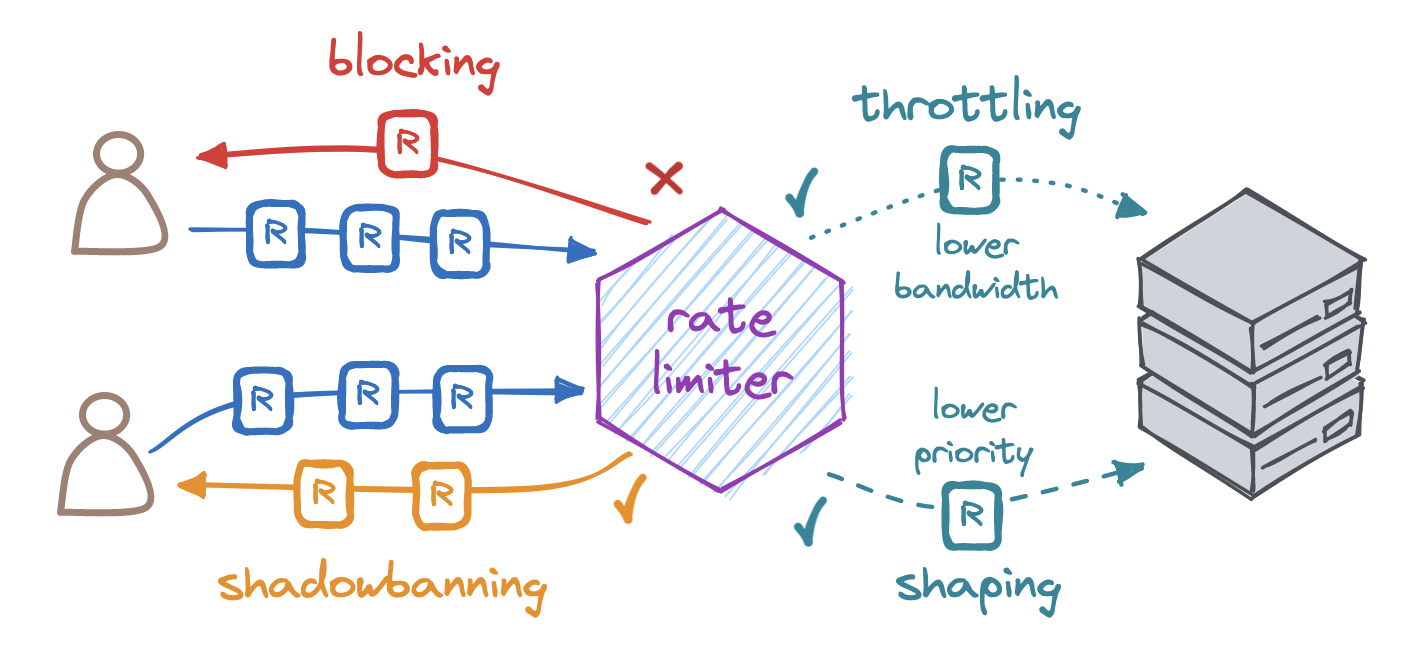
How do we respond when rate-limiting a request?
The most common response is to block the excess request by returning the HTTP status code 429 (Too Many Requests) or 503 (Service Unavailable), with headers indicating the rate limit and when to retry. We may also shadowban any identified abusers. Since an abuser who knows they have been rate-limited might try to circumvent the limit, we can choose to accept their excess request, return them the HTTP status code 200 (OK), and simply not process it.
Or we may choose to throttle (i.e. degrade) the service instead. Think of a storage service that lowers the bandwidth of a download, or a video platform that reduces the quality of a stream, or a financial API that introduces a delay in its responses. We may also choose to shape (i.e. deprioritize) the response. For instance, we could process requests from paying customers first, and queue up other requests for processing only after all priority customers have been served.
Where do we locate the rate limiter?
We can place the rate limiter at the edge of our system, at the entry point to our system, or inside our system, depending on the requirements.
-
Content delivery network: A CDN is a geographically distributed network of proxy servers serving content to nearby clients. Some CDNs, like Cloudflare, may be configured to rate-limit requests.
-
Reverse proxy: A reverse proxy is a server that sits in front of our multiple servers and forwards client requests to them. Some reverse proxies like Nginx offer rate-limiting options.
-
API gateway: An API gateway is an entry point to multiple related APIs, often to handle common functionality like authentication, routing, allow-listing, service discovery, etc. Amazon API Gateway, among others, is able to host a rate limiter to control access to groups of endpoints.
-
Application: For a more fine-grained approach, we may also write our own rate limiter and place it in our application. For example, we can create middleware to limit requests to designated endpoints based on user-level properties, such as their subscription type.
Where do we store rate-limiting state?
For a rate limiter to operate, we must track rate-limiting state, i.e. information about the number of requests made by each client in a time window. It is based on this state that we can decide whether to accept or deny a request.
The most straightforward option is in-memory storage. If we have a single server or store for rate-limiting state, we may choose to keep this state entirely in memory. This solution only fits a low-scale service - for higher-scale ones, we must choose between centralizing and distributing state storage.
If we store this state in a centralized store, we add latency to the response, create a potential bottleneck in our system, and run the risk of race conditions. Since on each request we read the state, increment it, and write it back to the store, it can very well be the case that multiple concurrent requests all read the same state, increment it, and write it back, bypassing our rate limit.
By contrast, if we keep this state in distributed storage, we can scale out horizontally to multiple stores, hence no bottleneck in our system. But in this case we will need to synchronize state across all our stores. That is, once the read-increment-write cycle completes in one store, we must update this state in all other stores to keep them in sync. And given the delay in updating state across all instances, note that this may end up introducing inaccuracies in rate-limiting state. Depending on the use case, these inaccuracies may or may not be tolerable.
What are the most common rate-limiting algorithms?
Fixed window counter is an intuitive first option. This algorithm divides time into fixed-size time windows and keeps a counter for each of them.
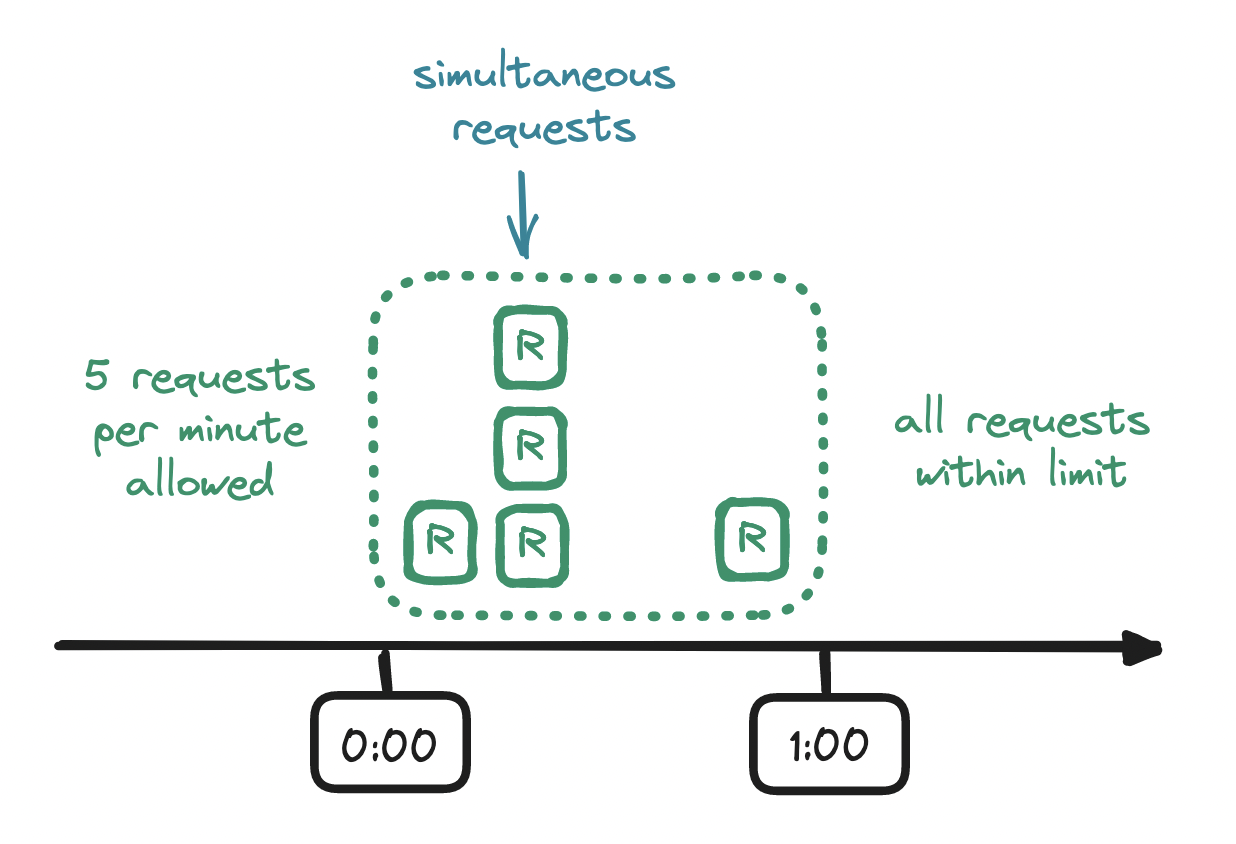
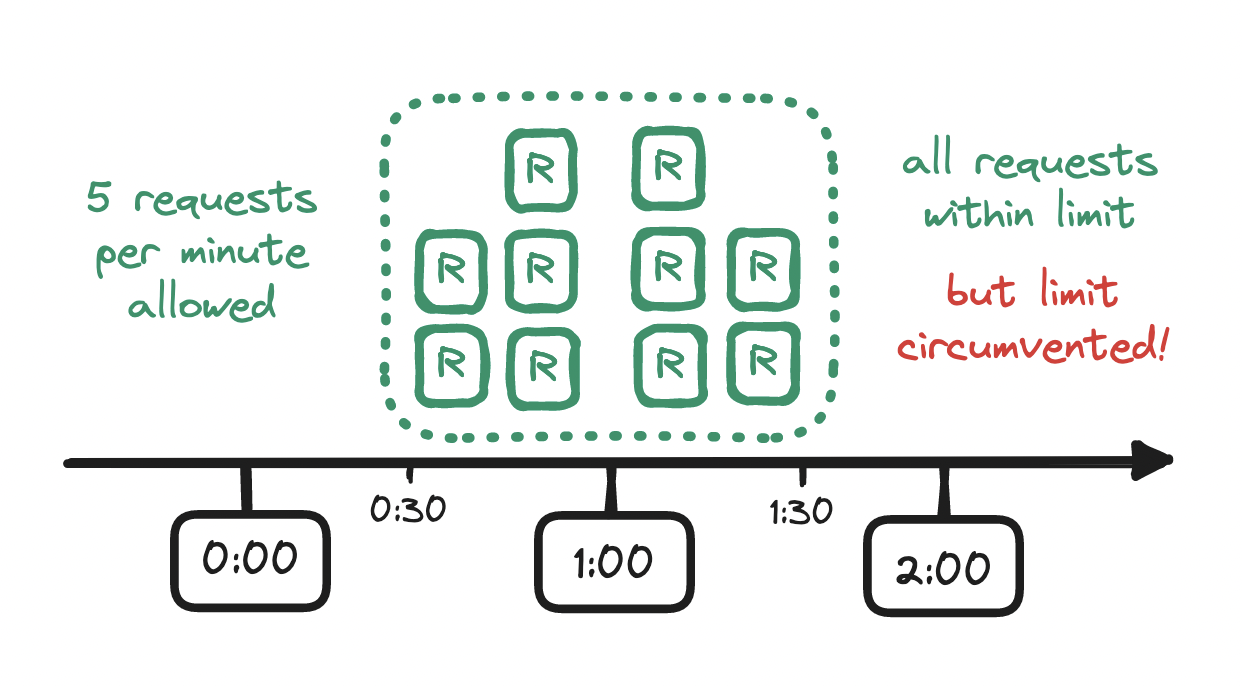
Every request arriving within a time window increments the counter for that time window, and once the counter exceeds the limit, any subsequent requests from the client are denied until the current time window ends and a new one begins. With a rate limiter that allows at most five requests per minute, if a sixth request arrives before the minute is up, the client's excess request is denied.
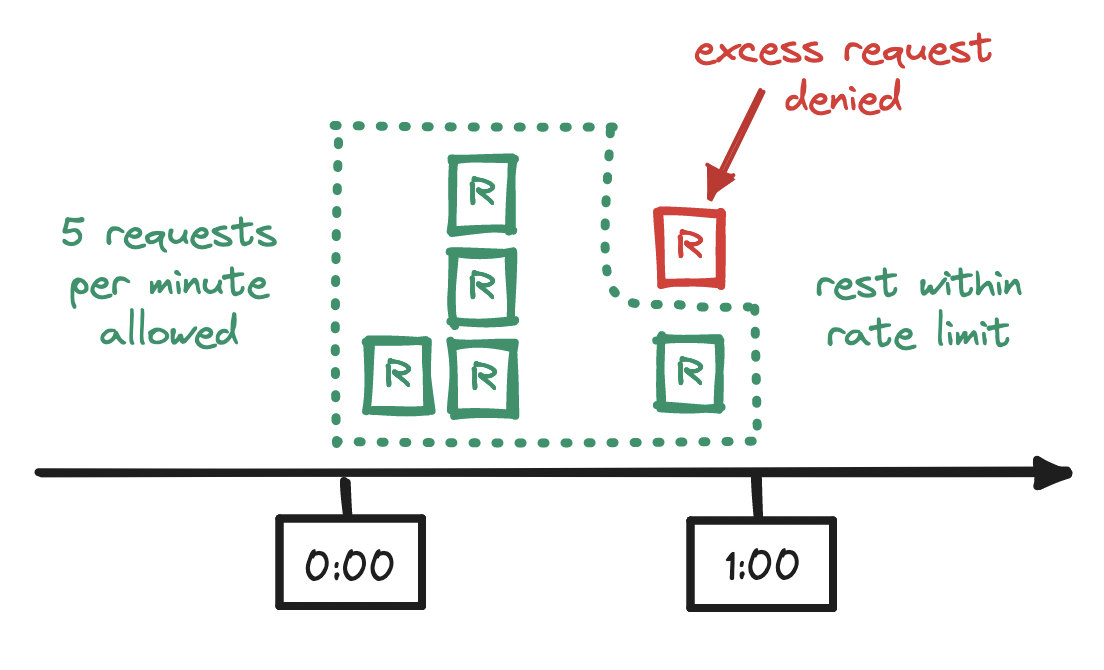
Notice, however, that this rate limit is enforced only within the edges of the time window that we have specified (e.g. from the start to the end of a minute) but not within a time window of equal length across those edges (e.g. from the midpoint of a minute to the midpoint of the next). If our limit is five requests per minute, and if a flurry of five requests arrives at the end of a minute, and if another flurry of five requests arrives at the start of the next minute, then we will have allowed twice as many requests as we should have allowed!
To mitigate this issue, we might reach for a sliding window log instead.
Instead of counters and time windows, this second algorithm relies on a log of timestamps. For each incoming request we add a timestamp to the log, and if we find that the addition caused the log size to exceed our rate limit, then we reject the request. And importantly, before checking the log size, we clear any outdated timestamps, i.e. timestamps outside the current time window. In short, we keep track of a sliding time window of timestamps.
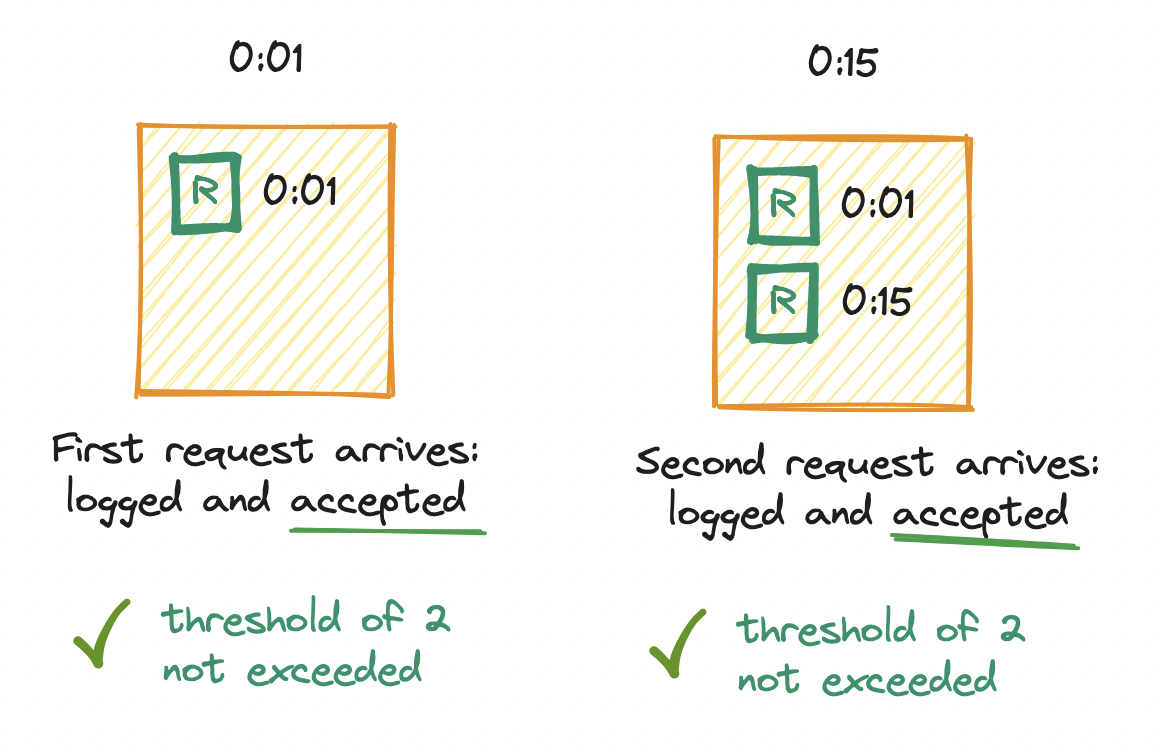
For example, imagine a rate limiter that allows up to two requests per minute. We deploy our service and set up an empty log. Immediately, at the first second (0:01), a request arrives. We add a timestamp to the log. Log size is now one, which does not exceed the limit of two, so the request is allowed. Later, at the fifteenth second (0:15), a second request arrives. Again we log the timestamp. Log size is now two, which does not exceed the limit of two, so the request is allowed.
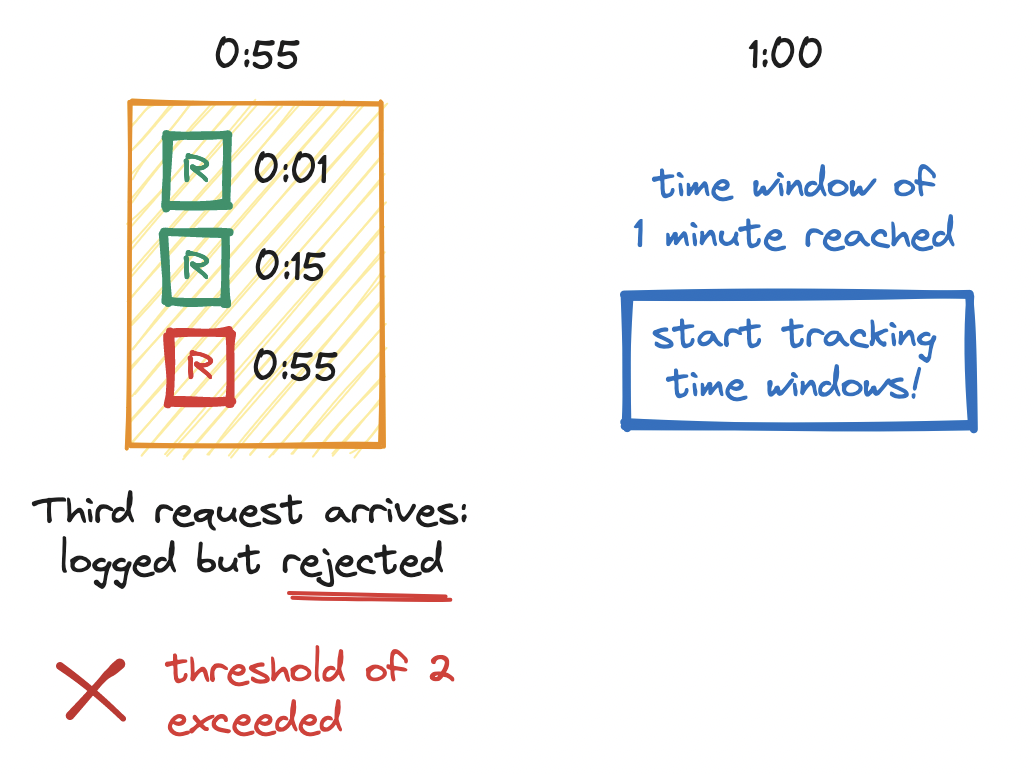
Next, at the fifty-fifth second (0:55), a third request arrives. We log the timestamp. The log size is now three, which exceeds the limit of two, so we deny the request. Soon after, at the top of the minute (1:00), we notice that the first time window has elapsed, so we make a mental note: from this point on, we must clear outdated timestamps before checking the log size.
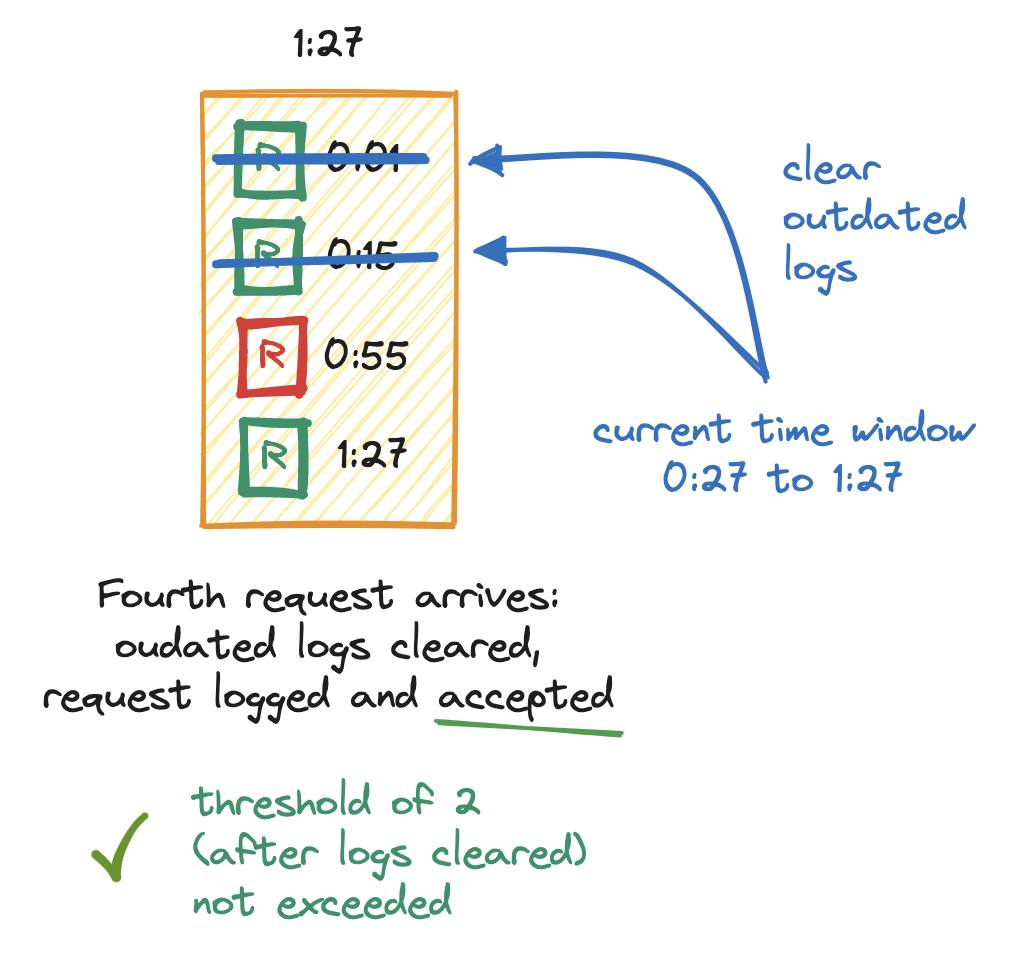
Then, at twenty-seven seconds into the first minute (1:27), a fourth request arrives. We add a timestamp to the log. Since we now know that we may have outdated timestamps in the log, we clear them - we look for any requests logged between the current point in time (1:27) and the start of its sliding window (0:27) and remove those requests from the log. Log size is now two, which does not exceed the limit of two, and so the request is allowed.
This way, we ensure no flurry of requests can slip by at the edges of the time window. But the sliding window log has its own issues. For one, this algorithm logs a timestamp for every single request, whether allowed or not, so it is memory intensive. For another, it is rather wasteful to perform work (i.e. clearing outdated timestamps) on every single request.
A more efficient solution, combining both approaches above, is the sliding window counter. This keeps two counters: one for the current time window and one for the previous time window. Based on them, we calculate how many requests arrived in the sliding time window, namely by weighting the requests in the last time window based on its overlap with the current time window. On every request, we calculate the total and allow or deny the request based on the limit.
To understand this calculation, let's walk through an example. Imagine a rate limit of seven requests per minute. So far, we have received five requests in the previous minute and three requests in the current minute, and then a new request arrives eighteen seconds into the current minute (1:18).
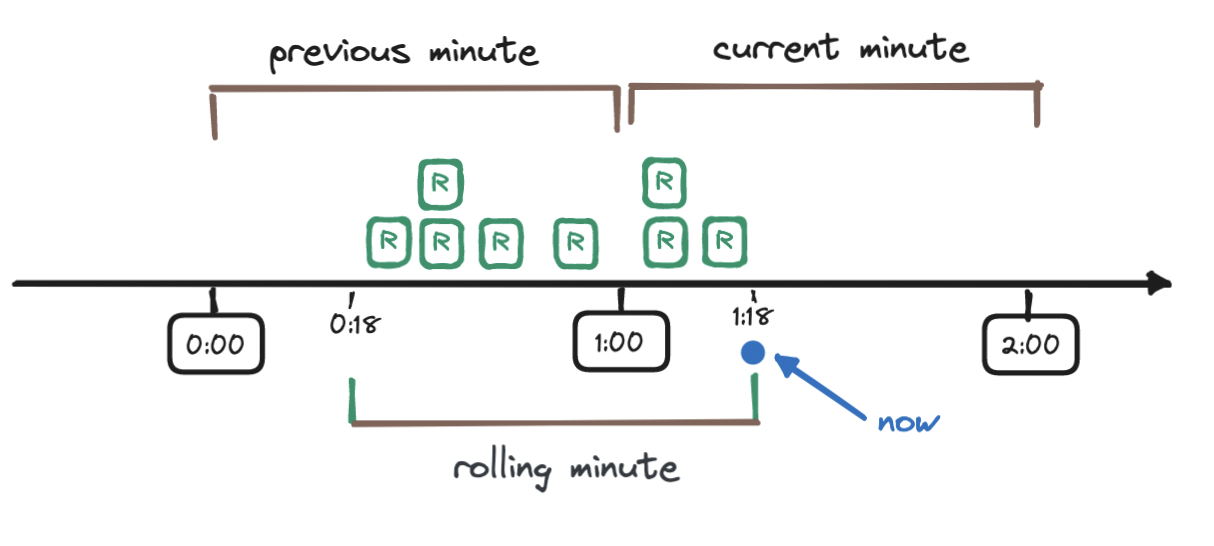
To calculate the weighted number of requests in the sliding window, we add the requests in the current window (three) to the result of multiplying the requests in the previous window (five) with the percentage of overlap of the sliding window and the previous window - this percentage is the weight.
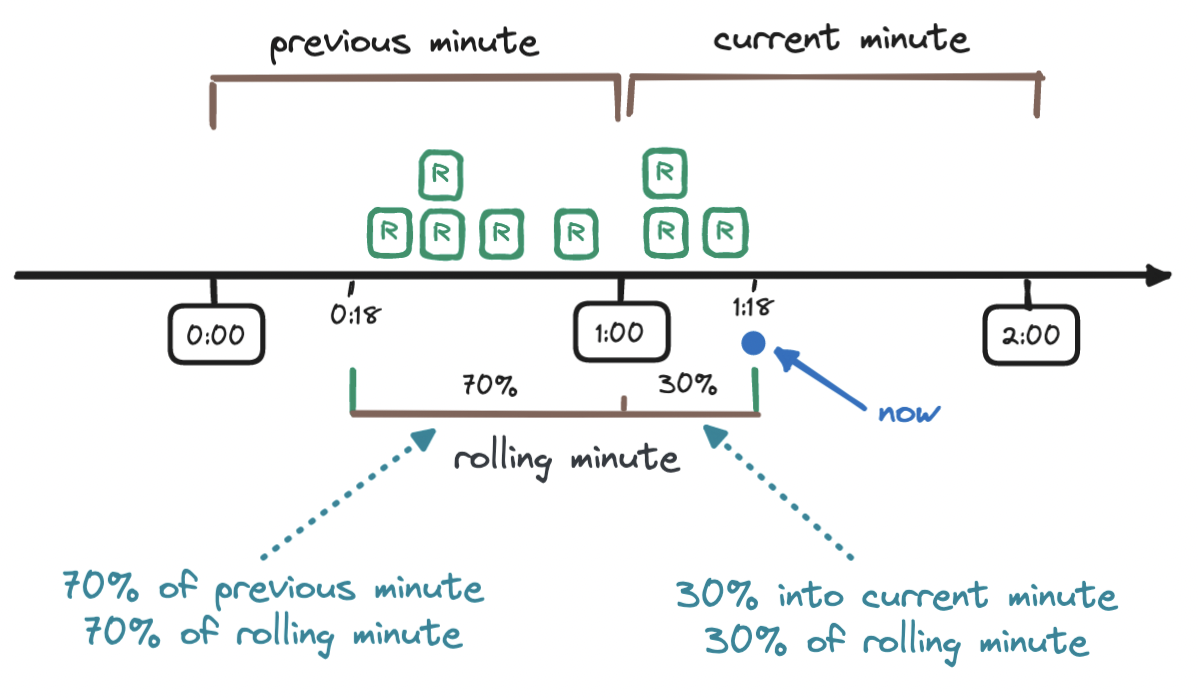
How do we find this percentage? We observe how far along we are into the current window (18 seconds, which is 30% of 60 seconds) and subtract this value from 100%, to obtain the weight, here 70%. Again, this percentage is how much of the sliding window is made up of the previous window. And now that we have the weight, we can work out the weighted number of requests in the sliding window:
3 + (5 * 0.7) = 6.5
Depending on the use case, we may round the resulting 6.5 up or down - here we round it down to 6. Since our rate limiter allows seven requests per minute, the request that led to this result is allowed.
The sliding window counter is less memory- and I/O-intensive than the sliding window log, while being more accurate than the fixed window counter. The sliding window counter, however, assumes that requests are evenly distributed across the previous time window, which might not always be the case.
A fourth algorithm, quite popular and easy to implement, is the token bucket.
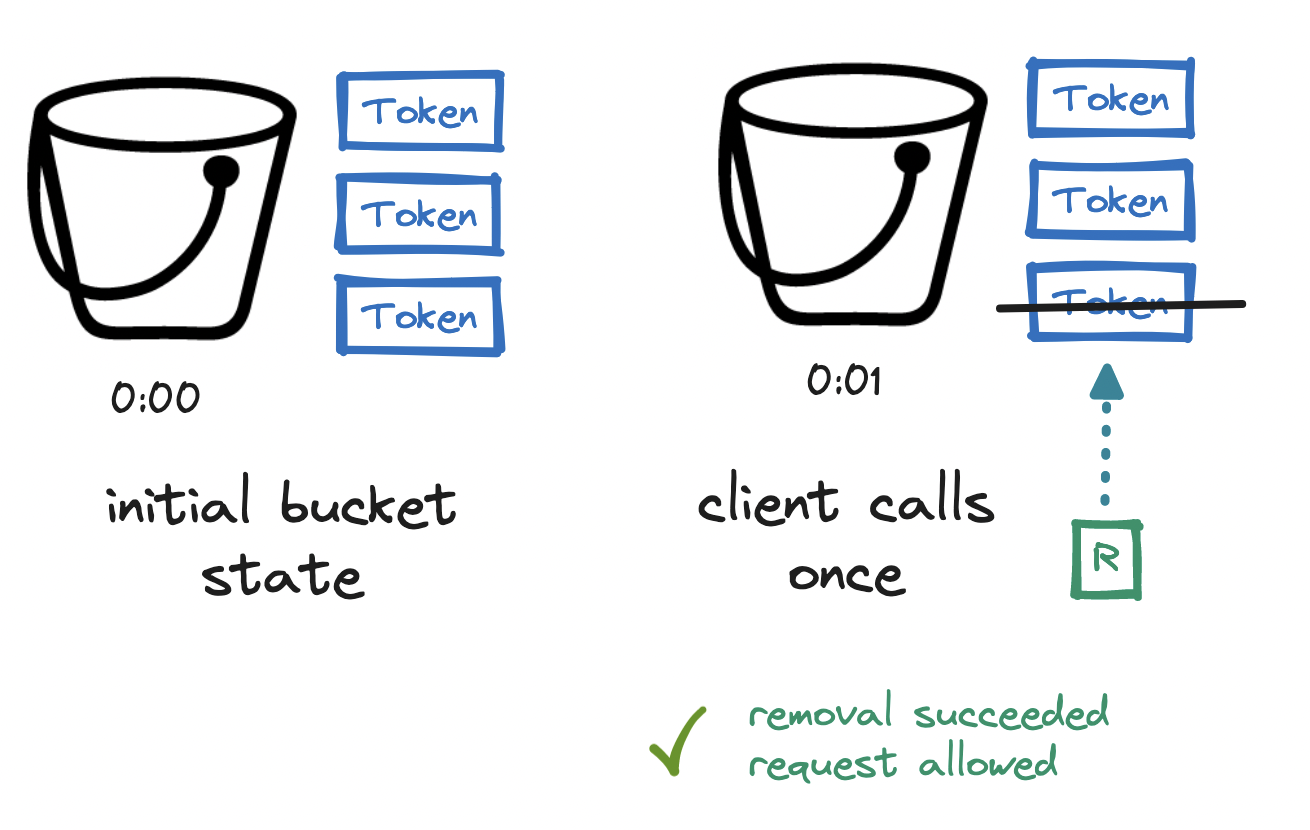
Imagine a bucket that can hold a number of tokens. Every second, the bucket is refilled with a number of tokens. Refilling a full bucket has no effect. Whenever a request arrives, we remove a token from the bucket and allow the request, but once we cannot remove a token because the bucket is empty, the request is denied. We are expressing our rate limit in terms of bucket size and refill rate.
Again, let's walk through an example. Imagine a rate limit of four requests per minute, expressed as a bucket size and refill rate of three. We begin with a full three-token bucket. At the first second (0:01), a first request arrives. We remove a token from the bucket and allow the request.
At the fifteenth second (0:15), two requests arrive. We remove two tokens from the bucket and allow the two requests. Our bucket is now empty. At the fifty-eighth second (0:58), a fourth request arrives. We try to remove a token from the bucket, but since we cannot remove a token from an empty bucket, we deny this fourth request.
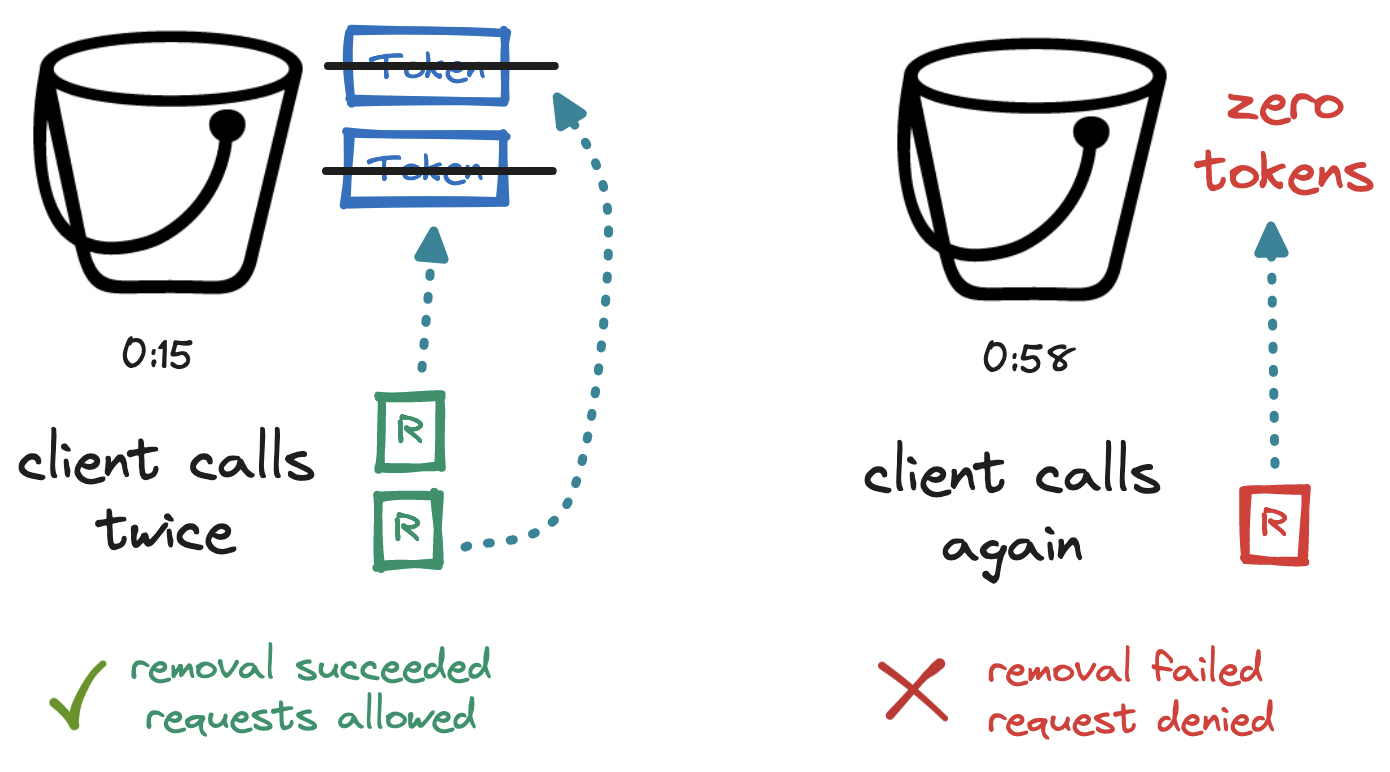
At the top of the minute (1:00), the bucket is refilled with three tokens. We return to the initial state, and so the process continues - no calculation needed.
A variation of the token bucket is the leaky bucket. Here we keep the bucket but discard the tokens. Instead, we use the bucket as a holding area for requests: requests are queued up and regularly flow ("leak") out of the bucket to be processed. If the bucket is filled to the brim, the incoming request is denied. The bucket is a queue, where the rate limit is expressed in terms of queue size and outflow rate.
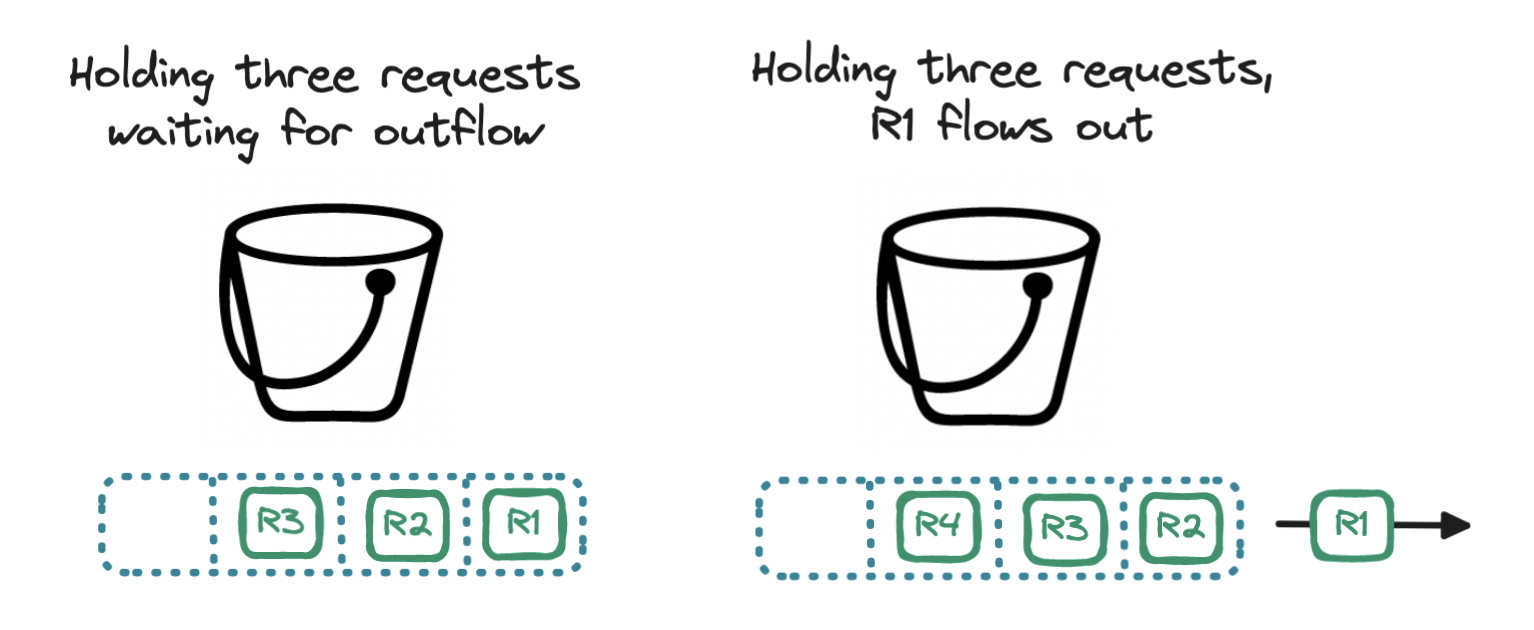
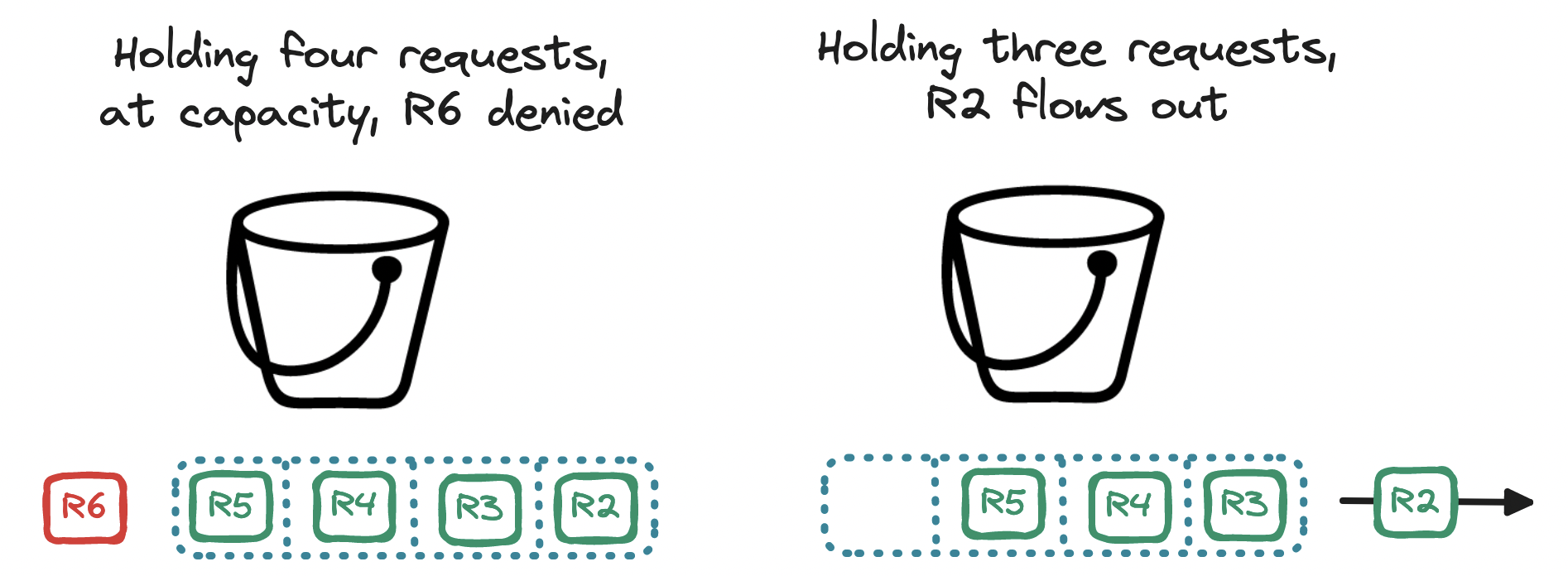
With the leaky bucket algorithm, requests are processed at a steady rate, protecting our server from requests arriving in bursts. This makes it apt for scenarios where a stable outflow rate is required. But note that if a burst of requests exceeds the queue capacity, older requests may stay in the queue for longer than expected, delaying the processing of newer requests. With a leaky bucket, users may experience longer wait times for their requests during periods of high traffic.