JavaScript Hard Parts by Will Sentance
2020-05-10T01:03:01.143ZJavaScript Hard Parts by Will Sentance
Sources:
- JavaScript: The Hard Parts by Will Sentance
- JavaScript: The New Hard Parts by Will Sentance
- The Hard Parts of Object Oriented JavaScript by Will Sentance
- Servers & Node.js: The Hard Parts by Will Sentance
- Hard Parts: Functional JavaScript Foundations by Will Sentance
Part I: Execution
- JavaScript has one single thread of execution, i.e. it executes code one line at a time.
- JavaScript has multiple execution contexts, i.e. environments where code is run.
- JavaScript uses the call stack to track where the thread is running at any given time.
- JavaScript uses scopes to determine what data the thread may access at any given time.
- JavaScript's scoping rules allow for the existence of closures.
- JavaScript uses micro- and macro-tasks to defer functionality in async execution.
JavaScript engine
How do you run JavaScript code?
JavaScript does not run by itself! You need a JavaScript engine to compile and execute your JavaScript code. A JavaScript engine is embedded in every web browser, such as V8 in Chrome and SpiderMonkey in Firefox.
JavaScript engines are complex pieces of engineering, with many moving parts. The most important ones are:
- memory,
- execution context, and
- the call stack.
When the browser loads your code, the JavaScript engine inside the browser...
- populates the engine's memory with your variables and function declarations,
- creates one big execution context and multiple mini-execution contexts to run your functions in,
- performs the actual work of executing the functions in memory using its single thread of execution: at first, in the big execution context, and then entering and exiting mini-contexts as needed, and
- keeps track of where it is as it enters and exits its many contexts, through the call stack.
These three—memory, execution context and the call stack—are the basic moving parts you need in order to understand synchronous (i.e. blocking) execution of JavaScript. But later, when we look at asynchronous (i.e. non-blocking) execution, we will need to add three more to our list:
- the event loop,
- the macrotask queue, and
- the microtask queue.
Execution context
What is an execution context?
An execution context is a useful environment for your code to run in:
- It stores variables and functions, in its creation phase.
- It runs functions on data, in its execution phase.
- It holds references to useful data: any parameters passed to it, its outer environment, etc.
When an execution context is created, JavaScript prepares space for any declared variables and functions. This preparation of space for the future contents of variables and functions is called hoisting. When hoisted, the names for variables and functions exist but they do not yet point to any values, so the hoisted variables and functions are set to undefined, i.e. named but not yet pointing to a value, or more formally: uninitialized.
console.log(a); // → `undefined` (variable exists, but no value assigned)
var a = 'Hello World!';
console.log(a); // → "Hello World!" (variable exists and has value assigned)
What types of execution contexts are there?
JavaScript has two types of execution contexts: global (not inside a function) and local (inside a function), each with its own memory.
Global context
Admittedly, "not inside a function" is not a great definition. What is the global context? Any JavaScript code that is not inside a function is contained within a single object, known as the head object. We call it window in the browser and global in Node.js and it can be referenced via the variable this, which we will cover later.
The head object automatically encapsulates all of your code and all of JavaScript's built-in code. All code is automatically placed inside the head object for execution.
Head object vs. global property
The head object is an all-encompassing object for running all code. A global property, on the other hand, is a property on that head object that is not scoped to a specific function. In practical terms, when you create a global variable, you are actually adding a property to the head object and making it visible all across the code base.
A reference to the head object is often implied: alert() is equivalent to window.alert(), unless you have overwritten that function.
Global to local to global
Now that we know what "global" and "local" mean, we can follow the thread of execution as its runs through our code.
JavaScript starts executing inside the global execution context—but whenever a function is called, a local execution context is created, at which point the thread of execution enters the local context, runs the code inside that local context, the local context is destroyed, and the thread of execution exits back out into the global context, where it keeps running until another function is called and another local context is created.
Whenever a function is called—whenever we create a local context into which the thread of execution enters—we say that the function or local context is pushed onto the call stack. When the function is finished executing and the local context is destroyed and the thread of execution exits out into the global context, we say that the function or local context is popped off the call stack.
Call stack
If there are multiple execution contexts, how does the thread of execution know where it is running?
JavaScript uses the call stack to keep track of where the thread is running at any given time.
A stack is a container that only allows you to put in and take out pieces of data on the same end. Think of a stack of dishes: they can only be placed on the top and removed from the top, that is, each dish is to be taken out in the inverse order it was placed in—otherwise, grabbing a dish at the middle or at the bottom risks disaster! In other words, the last piece of data to enter the stack is the first one to come out, following the last-in-first-out (LIFO) order. In a call stack, what is put in and taken out of the stack are function calls.
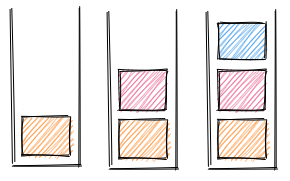
The number of calls in the stack indicates where the thread is. Let's see how this works, step by step.
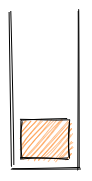
When the thread of execution is in the global context, the call stack is empty.

Whenever a function is called, creating a local context into which the thread of execution enters, that function call is now placed into the stack. In other words, that function call is what the thread of execution is currently running.
If a function is placed in the call stack, a local context is created, so the thread of execution enters it and runs the function. When the thread of execution has finished running that function, the local execution context is destroyed, and that function is popped off the stack. When the stack is empty, the thread of execution knows to return to the global execution context.
However, what if, before the thread of execution has actually finished running the function, the thread encounters yet another function call, that is, a function call right inside the function the thread is currently running? In that case, another local context is immediately created inside the current execution context and another function call is pushed onto the call stack. We were inside one local context, and now we enter another, nested local context. Think of opening a matryoshka doll, only to reveal another smaller inner doll, beckoning you to see what's inside.
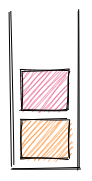
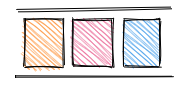
The thread then has to enter that new local context to run the nested function. Once the thread has finished running that nested function without finding any more nested functions, the nested local execution context is destroyed, and the nested function is popped off the stack.
The stack is back to one call and almost empty. Now the thread has returned to the previous local context, so it finishes running that function and it is now popped off the stack. At this point, the stack is finally emptied out and so that the thread now can, at long last, return to the global execution context.
Scope
If there are multiple execution contexts, how does the thread of execution know what data it can access?
JavaScript uses scope to determine what data the thread may access at any given time. Think of scope as the bounded area visible to the thread of execution, that is, the data environment available at a given line in a section of code.
Visibility only works from the inside out. A context can see into its parent context, all the way up to the global context, but not the other way round. When looking up data, JavaScript follows this scope chain, from the inside out, until reaching the global context.
function b() {
console.log(myVar); // lookup `myVar`: `b` → `global`, value: `1`
}
// `a` (sibling local context) was not searched!
function a() {
var myVar = 2;
b();
}
var myVar = 1;
a();
If you nest the variable in a function in another function, the lookup goes up to the immediate outer environment, and its immediate outer environment, until reaching the global context.
Searching for a variable from inner to outer context:
function a() {
function b() {
console.log(myVar); // lookup for `myVar`: `b` → `a`, value: `2`
}
var myVar = 2;
b();
}
var myVar = 1;
a();
Searching for a variable from inner to outer to global context:
function a() {
function b() {
console.log(myVar); // lookup for `myVar`: `b` → `a` → `global`, value: `3`
}
b();
}
var myVar = 3;
a();
Now, remember that each local context holds a reference to its outer environment. JavaScript is statically scoped: where a function is created determines what data the function will have access to wherever it is run. That is, scope is determined at its declaration, not invocation.
Conditional statements with if and looping statements with for do not create a scope.
So in sum:
- The global execution context is visible to the thread everywhere in your code.
- A local execution context is visible only to the thread...
- inside that local context, and
- inside that local context's inner environment.
Closure
Given these scoping rules, what if a function refers to data outside of itself?
Remember: The lookup chain works inside out (i.e. inner functions can look at their outer environment) and JavaScript functions are statically scoped (i.e. they retain a reference to their outer environment).
The natural consequence of these scoping rules is that JavaScript allows for the existence of a closure, a function that can access and remember its outer variables, no matter where the closure is executed.
A closure "closes over" (i.e. grabs onto) the external data that it needs so that it is fully equipped to execute anywhere. Think of this portable store of needed external data as a "backpack", which the function packs where it is created and uses wherever it is called.
let b = 1; // highlight-line
// ↑ highlight: `b` is being closed over by `closureSum`
function closureSum(a) {
return a + b;
}
// Elsewhere in your code...
console.log(closureSum(2)); // argument `2` + closed over `1` → logged: `3`
// We can use `closureSum` anywhere else and it will remember `b`!
What data is closed over? A closure's needed external data is the variables that the closure needs in order to run and that are defined in the function's outer environment but not in its parameters or body. If the closure refers to external data but it does not actually need that data in order to run, then that unnecessary data is not closed over. If no external data at all is needed to run the function, then the function is not a closure.
Closures and closed-over variables
Closure is a function able to access and remember the variables that it needs to run and that were located in its enclosing scope. Closed-over variable is the variable itself, the external necessary data that is grabbed, which is also called, in fancier circles, closed-over variable environment or persistent lexically scoped variable.
Closures store state (i.e. data being changed over time), effectively preserving it between function calls. How do we access this store of data? The closed-over variable or "backpack" is accessible via a function's hidden property [[scope]].
Note the relationship between scoping rules and closures. A closure can first access its outer variables thanks to inside-out scoping and can then remember them (i.e. keep accessing them) thanks to static or lexical scoping. Recall that static or lexical scoping means that where the function is created determines what data it will have access to wherever it is run. If a function happens to need external data when created and that data is nearby, then the function then just reaches over and packs it up! A closure closes over what it needs right then and there where it is created. A closure is thus the combination of a function and the scope in which it is created.
Closed-over variables can be read and they can also be updated, which means that closures have persistent memories! In fact, if we were to create and return a function out from another function, that returned function would still able to access its parent function's scope. This principle enables the implementation of once(), memoize(), iterators, generators, the module pattern and promises.
Asynchronicity
If JavaScript has a single thread of execution, how do we prevent time-consuming operations from blocking execution of quickly-executable code?
Since JavaScript is single-threaded, so far we have been naturally thinking of execution in its simplest sense: synchronous or one line at a time. The thread executes one line of code, and only after that one line is done can it actually move on over to the next. Each line is executed in the order in which it exists in the code. Sync execution is therefore also called "blocking", i.e. each line effectively prevents the next one from running. This order of execution is enforced at all costs.
But always enforcing this order of execution can become inconvenient. For example, if we know a line will take a long time to be executed, we might want that time-consuming line to be executed while also allowing later lines to run. We have now started to think of execution in another sense: asynchronous or more than one line at a time. Async execution is also called "non-blocking", that is, the thread is free to continue to run the rest of the code. As a result, we can delay the execution of a specific section of code that depends on the result of a time-consuming task, without blocking the rest of the lines from being executed while we wait.
In async execution, we:
- initiate a task that takes a long time (e.g. an HTTP request for a piece of data),
- move on to more regular sync code in the meantime (i.e., tasks that do not depend on that data), and
- finally execute a specific section of code once the initial task is complete (once the data we requested is available).
We have effectively deferred functionality.
In JavaScript, deferred functionality is delegated to the browser. Whenever you call setTimeout() or fetch(), you are actually using facade functions, that is, "fronts" for functions actually implemented in, and executed by, the browser, not in JavaScript. These are handy tools in the browser that are accessible from JavaScript.
Facade functions are not built-in JavaScript functions—they are part of the browser API.
Whenever you call a facade function, that functionality is delegated to the browser, and so the thread moves from the facade function straight on to the rest of your code. Think about it: since JavaScript is single-threaded, it is only natural to rely on a third party like the browser to handle time-consuming tasks.
const sayHello = () => console.log('Hello');
setTimeout(sayHello, 1000); // delegated to browser, goes off 1 second later
console.log('Me first!'); // printed first despite being located after
We can defer a task, but how do we track and handle its completion?
In JavaScript, we use a promise...
- to track the completion of a time-consuming task, and then
- to run code that acts on the result of that task.
A promise is thus a placeholder for that future result, coupled with the function to be triggered when the result is available, or callback.
Remember that facade functions are those implemented in, and executed by, the browser. Promises enable you to attach a specific section of code to the result of a task to be completed by the browser. Thus, calling a facade function usually has two immediate results:
- as we said, initiating browser work that will go on in the background, and also
- returning a promise, which is to receive the result of that browser work and run a function on the result once it is available.
For example, say you initiate a time-consuming task such as calling fetch() to retrieve a piece of data. Recall that fetch() is a facade function, whose functionality is handed off by JavaScript to the browser. So, while the browser is busy sending out your HTTP request to the server and getting back a response (i.e. while functionality is being deferred), you are immediately handed back a promise, a placeholder for that future result. In the promise you were given, you now can, for instance, specify that you will want to console.log() that future result—all the while the rest of your code (i.e. the code that does not depend on that future result) can continue running unabated.
Internally, a promise has:
- a
valueproperty, which will receive the future result, and - an
onFulfilledproperty, which contains the callback to be run once the result is available.
Promise.then(fn) is used to store the callback fn in the promise's onFulfilled property. That fn callback will be run as soon as the promise's value property receives a result. Also, as a convenience, the result in value will be automatically passed in as an argument to fn.
When is the promise's callback allowed to be invoked if we have sync code executing?
Let's review the last bit of the process. Once the browser completes its work, it returns a result. That result is placed into the promise. The promise detects that it contains a result and is ready to invoke the callback set to run once the result is available. But remember—regular sync code has been executing ever since we delegated functionality to the browser. So when exactly is the promise's callback to be run? Do we simply allow the callback to "interrupt" our regular sync code?
No. Once a promise's callback is ready to be invoked, its callback is sent to the microtask queue, where it must wait until it can move onto the call stack. A promise's callback is never sent directly to the call stack.
A queue is a container where pieces of data enter on one end and exit from the other, following the first-in-first-out (FIFO) order. The first item to come into the queue is the first item to come out of the queue, so if many callbacks are queued up, they move out onto the call stack in the order in which they arrived at the queue.
Here is JavaScript's rule to prevent your sync code from being "interrupted". The call stack must be empty before a promise's callback is allowed to go from the microtask queue onto the call stack. In other words, only when all regular sync code in the global context has finished executing is the promise's callback allowed to be run.
There is a construct called the event loop that constantly checks "Is the call stack empty?" and if so, "Is there a callback waiting in the microtask queue?". We are free to delegate a function to the browser, but the event loop decides the order of execution of any callbacks to be run on the future result of our delegated function.
Do all facade functions return a promise?
Actually, no. There is a last bit of complexity. Facade functions can be:
- promise-returning like
fetch(), whose promise's callbacks are directed to the microtask queue, or - non-promise-returning like
setTimeout(), whose callbacks are directed to the macrotask queue.
A macrotask queue is a different queue for this second type of facade function. Remember the microtask queue gets the callback of a promise; the macrotask queue gets all the rest.
The microtask queue has priority over the macrotask queue. The event loop checks:
- if the call stack is empty, and then
- if the microtask queue (for promise callbacks) is empty, and then
- if the macrotask queue is empty.
In that order.
For example, if you defer functionality with setTimeout(fn) (non-promise-returning facade function) and then you defer functionality with fetch(fn) (promise-returning facade function), the order of execution becomes:
- sync code,
fncallback forfetch()in the microtask queue, andfncallback forsetTimeout()in the macrotask queue.
Part II: Object-Oriented Programming
- Object-oriented programming is characterized by encapsulation, inheritance, abstraction and polymorphism.
- To implement its own version of inheritance, JavaScript uses the prototype lookup chain.
Concept
Object-oriented programming (OOP) is a strategy for organizing and sharing code. Specifically, in OOP we...
- organize code into custom structures ("objects") that contain data ("fields") and procedures for acting on that data ("methods"), and
- share said data and procedures ("fields and methods") among our custom structures ("objects").
OOP has a dual purpose:
- Gathering code into collections of fields and methods allows you to keep related code together.
- Sharing fields and methods among related objects allows you to avoid code repetition.
For example, think of an Employee object ("parent") with a salary field and an applyRaise() method. This object can have other related objects ("children"), Manager and Developer, sharing the same salary field and applyRaise() method, while also having other fields and methods that are unique to each child: a Developer may have a programmingLanguage field, whereas a Manager may have a managedEmployees field.
Conceptually, the two main principles being discussed are known as:
- encapsulation, organizing code into collections of fields and methods, and
- inheritance, giving a parent's fields and methods to its children.
But there is more! We can also tweak our objects and their relationships, by deciding...
- which of an object's field and methods should be accessible (i.e. visible and callable) when using the object, and
- that a child should have its own version of a method (i.e. same name, different functionality) inherited from a parent.
Conceptually, these two additional principles are known as:
- abstraction, hiding an object's internals and exposing only its essential features, and
- polymorphism, overwriting a parent's method with a child's own version.
We will focus on JavaScript's implementation of the first two principles: encapsulation and inheritance.
Implementation
How does JavaScript implement encapsulation?
To encapsulate fields and methods into an object, you might start by simply creating an object and populating the object with fields and methods:
// create object
const user = {};
// populate object with two fields and one method
user.name = 'john';
user.score = 10;
user.increaseScore = function () {
user.score++;
};
To keep this tidy, you can also automate encapsulation with a factory function:
// function for automatically creating and populating an object
function createUser(name, score) {
const user = {};
user.name = name;
user.score = score;
user.increaseScore = function () {
user.score++;
};
return user;
}
const newUser = createUser('john', 10);
Or you can automate encapsulation with a constructor function:
function User(name, score) {
// highlight-line
// ↑ highlight: capitalized function name
this.name = name; // highlight-line
// ↑ highlight: `this` keyword
this.score = score;
this.increaseScore = function () {
user.score++; // highlight-line
};
} // ↑ highlight: no `return` statement
const newUser = new User('john', 10); // ← highlight: `new` keyword
But this last version is rather confusing. What are all these highlighted features? How exactly does a constructor function actually work? To understand encapsulation through constructor functions, we first need to understand how JavaScript implements inheritance, the second principle we discussed above. Then we will return to revisit constructor functions.
How does JavaScript implement inheritance?
Remember: inheritance means sharing fields and methods among objects related to each other, for the purpose of avoiding repetition. The goal is code reuse, i.e. to avoid creating and storing multiple copies of the shared code, which is inefficient.
Various programming languages implement inheritance slightly differently, but JavaScript's implementation of inheritance is quite different from the rest. While most programming languages implement inheritance using classes (sets of blueprints for creating actual objects), JavaScript implements inheritance using prototypes (objects as base objects of other objects).
In JavaScript, each object holds a reference (think of an arrow) pointing to another object. The object being referred to (think of a target) is the object's prototype or base object.
In JavaScript's prototypal inheritance, we...
- create a single bundle of shared fields and methods, and
- have objects refer to that bundle.
The bundle is the prototype (target) of the objects (arrow-holders). The object's reference (arrow) links that object to its prototype or base object.
This way, a first object can refer to a second object as its prototype, and that second object can in turn refer to a third as its prototype, and so on. When you access an object's field or call one of its methods, JavaScript looks for the field or method in the object itself and, if it does not find it, then JavaScript automatically walks up the prototype chain to continue the search. If you try to access a property that is not contained in an object, JavaScript will search for the property following the prototype chain all the way up.
__proto__ property
But what exactly is this reference to the prototype? And how do we control it?
Every JavaScript object has a hidden property called __proto__ that refers to its prototype or base object. If necessary, JavaScript can and will follow your object's __proto__ to its prototype and that object's __proto__ to its own prototype, and so on.
To assert control over __proto__, you can rely on Object.create() and Object.setPrototypeOf().
Object.create()
To control an object's __proto__ at its creation, use Object.create().
First remember the simple factory function example:
// simple factory function
function createUser(name, score) {
const user = {};
user.name = name;
user.score = score;
user.increaseScore = function () {
user.score++;
};
return user;
}
Now refactored to use an object prototype:
// refactored factory function
function createUser(name, score) {
const user = Object.create(userFunctionStore);
// `user` has its `__proto__` (reference)
// set to `userFunctionStore` below (prototype)
user.name = name;
user.score = score;
return user;
}
// separate object as prototype, containing a shared function
const userFunctionStore = {
increaseScore: function () {
this.score++;
},
};
With this refactoring, every object returned by createUser() will have access to userFunctionStore. You can now simply add functions to userFunctionStore and they will be automatically accessible to every user you create.
If you do not assert control over an object's __proto__ at its creation, then __proto__ will point by default to Object.prototype, which is the God object, a built-in bundle of commonly used fields and methods whose __proto__ is set to null. The prototype chain ends at Object.prototype. In the example above, we asserted control over the __proto__ of user, setting it to our userFunctionStore. But we did not assert control over the __proto__ of userFunctionStore, so its __proto__ defaulted to Object.prototype.
Object.setPrototypeOf()
To control an object's __proto__ after its creation, use Object.setPrototypeOf().
For example:
// first factory function
function createUser(name, score) {
const user = Object.create(userFunctionStore);
// `user.__proto__` set to `userFunctionStore`
user.name = name;
user.score = score;
return user;
}
// first separate object, containing a function shared among all users
userFunctionStore = {
sayName: () => console.log("I'm " + this.name);
}
// second factory function
function createPaidUser(paidName, paidScore, accountBalance) {
const paidUser = createUser(paidName, paidScore);
// `paidUser.__proto__` initially set to `userFunctionStore`
Object.setPrototypeOf(paidUser, paidUserFunctionStore);
// `paidUser.__proto__` now set to `paidUserFunctionStore`,
// so `paidUser` now has access to `paidUserFunctionStore`
paidUser.accountBalance = accountBalance;
return paidUser;
}
// second separate object, containing a function shared among all paid users
const paidUserFunctionStore = {
increaseBalance: function() {
this.accountBalance++;
}
}
Object.setPrototypeOf(paidUserFunctionStore, userFunctionStore);
// `paidUserFunctionStore.__proto__` now set to `userFunctionStore`
// `paidUser` now has access to both `paidUserFunctionStore`
// and `userFunctionStore`
const payingJohn = createPaidUser("John", 8, 25);
payingJohn.sayName();
In short, JavaScript's implementation of inheritance is a prototype lookup chain. By controlling __proto__ with Object.create() and Object.setPrototypeOf(), we are effectively shaping that prototype lookup chain for JavaScript to follow.
A note on semantics
The prototype's fields and methods are not passed to the object: the object can access the prototype's fields and methods, but these will still remain in the prototype. This is why some people dislike the term "prototypal inheritance" in JavaScript, claiming it more precise to think of a connection between two objects, rather than a passage of variables and functions from one to another. Whatever the term, always think of JavaScript objects as holding references to variables and functions defined elsewhere, as opposed to actually having them.
prototype property
As we have seen, an object has a property pointing another object as that object's prototype, e.g. the payingJohn object has a reference pointing to the paidUserFunctionStore object. To state the obvious: these are two objects linked through an object-to-object relationship.
Now, in JavaScript, note that functions can have properties just like objects:
function multiplyBy2(num) {
return num * 2;
}
multiplyBy2.stored = 5;
// A value has been stored in a function's property!
// It works just like an object property.
If a JavaScript function can have have properties, each with a name and a value, then it follows that a function is an object with properties. Remember, a function is simply a container of functionality that can be invoked using parens (). That container of functionality may have properties, each with a name and a value, just like an ordinary object. In fact, a function can be assigned to a variable or stuffed in an array or in an object. Further, a function can be passed to, and returned from, a function. A function has properties because it is an object. This is why we say that functions are "first-class citizens" in JavaScript.
To expand on this, functions can have properties, and not all function properties are function-related! Every JavaScript function is actually a function-object combo, containing:
- function-related properties such as
argumentsandname, and also - an object-related property, namely
prototype.
When a function is created, it is automatically given a prototype property, which is an empty object. A function's prototype property is not hidden and by default has an object as its value.
multiplyBy2.prototype = {};
Here the terminology might start to become a bit dizzying, so be sure to mind the differences between an object's __proto__ property and a function's prototype property:
__proto__ property |
prototype property |
|---|---|
The __proto__ property belongs to an ordinary object. |
The prototype property belongs to a function (function-object combo). |
The __proto__ property is hidden. |
The prototype property is not hidden. |
The value of __proto__ is another object. |
The value of prototype is an object intended to contain other variables and functions. |
__proto__ is an object's hidden property (a reference, or arrow) with another object as its value (its prototype, or target). prototype is a function's non-hidden property with an object as its value (container of variables and functions).
Quick aside
Note that the prototype property is in fact also present in Array. Think back to every time you have used push(), join(), etc. All these built-in array-related functions are actually stored inside an array at Array.prototype. The docs at Mozilla Developer Network remind you of this whenever you need to look up a method. You can also view all array-related functions by entering Array.prototype in your browser console.
Array.prototype = [
concat,
push,
join,
map,
// and many many others
];
Whenever you create an array and then use a built-in array-related function, JavaScript first looks for that function in your array and, when it does not find it, your array's hidden property __proto__ directs JavaScript to Array.prototype, i.e. the array that stores the functions shared by all arrays.
const myArray = [];
myArray.push(1);
JavaScript first searches for the push method in the user-defined myArray, where the method is not found. JavaScript then follows myArray.__proto__ to Array.prototype and yes, JavaScript does find the push method in Array.prototype.
Now, what is the practical purpose of a function's prototype property?
Just as you can create an object as a bundle of shared functions and link other objects to the bundle via __proto__, you can automate object creation with a constructor function and add shared functions to the constructor function using its prototype.
Again, first remember the simple factory function example:
function createUser(name, score) {
const user = {};
user.name = name;
user.score = score;
user.increaseScore = function () {
user.score++;
};
return user;
}
Now refactored to use a function's prototype property:
function createUser(name, score) {
// by default, `createUser.prototype` is an empty object
const user = {};
user.name = name;
user.score = score;
return user;
}
// add a shared function inside the `createUser.prototype` object
userCreator.prototype.increaseScore = function () {
this.score++;
};
Now that we understand __proto__ and prototype, we can revisit how constructor functions work!
Revisited: How does JavaScript implement encapsulation?
new
Remember that we can automate encapsulation with a constructor function:
function User(name, score) {
// ↑ highlight: capitalized function name
this.name = name; // ← highlight: `this` keyword
this.score = score;
this.increaseScore = function () {
user.score++;
};
} // ↑ highlight: no `return` statement
const john = new User('john', 10); // ← highlight: `new` keyword
Now we are better equipped to understand these four features of the constructor function.
Of these four highlights, we can explain the first one right away. By convention, a constructor function's name, as in User, is capitalized to make it clear that the function is intended to be used with the new keyword. It is simply a convention borrowed from OOP languages where classes are capitalized.
Now, when a function is called with the new keyword, it automatically:
- creates a new empty object inside the body of the function,
- declares a variable called
thisand sets it to that new empty object inside the body of the function (*), - sets the new empty object's
__proto__to the constructor function'sprototype(**), and - returns the new object out from the function.
(*) Why? To allow you to populate the newly created object with fields and methods before it is returned out.
(**) Remember that an object's __proto__ refers to another object as its prototype. The other object (target) being referred to here is the constructor function's object-side prototype property, which has as its value an object intended to contain shared variables and functions.
In a constructor function, this is always used inside the body of the constructor function, while new is always used when calling the constructor function. In this context, this is the object in the process of being created (think of a product being assembled on an assembly line) and new is the directive for the constructor to create the actual object (think of a purchase order given to a manufacturing plant).
By using the new operator with a constructor function, we are ordering JavaScript to make for us an object that is an instance of that constructor function. We know that the new object will be an instance of that constructor function because it will have a __proto__ reference to its constructor's prototype property, which is a container for shared fields and methods.
An object from a constructor has the object's __proto__ pointing to the constructor's prototype, not to the constructor itself! This allows objects from that constructor to refer to the constructor's bundle of shared fields and methods.
For example:
function User(name, score) {
// by default, `User.prototype` is an empty object
this.name = name; // add field to new object
this.score = score; // add field to new object
this.sayHi = () => console.log('Hi!'); // add non-shared method
}
// now add a shared function inside the `User.prototype` object
User.prototype.increaseScore = function () {
this.score++;
};
const john = new User('john', 10);
In this example, john.__proto__ refers to User.prototype, which is an object containing increaseScore(). This way, john has to its own fields and methods as well as access to the functions in its constructor's prototype!
class
We have seen how a constructor function allows you to automate encapsulation, as you place an object's fields and methods inside the constructor and shared methods inside the constructor's prototype. But how do classes fit into this?
In JavaScript, a class is nothing more than a joint declaration of fields and methods that would be declared separately if using a constructor function's prototype property. A class is syntactic sugar over a constructor function and its prototype property.
Separate → constructor function and its prototype property
function User(name, score) {
this.name = name;
this.score = score;
}
User.prototype.increaseScore = function () {
this.score++;
};
Joint → class with constructor and method
class User {
constructor(name, score) {
this.name = name;
this.score = score;
}
increaseScore() {
this.score++;
}
}
Part III: Functional Programming
- In FP, we ensure that functions only change data inside themselves (immutability).
- In FP, we aim to combine small functions into larger tasks (composition).
Concept
Object-oriented programming (OOP) is a strategy for organizing and sharing code, and so is functional programming (FP). In FP, we ensure that functions only change data inside themselves (immutability) and aim to combine small functions into larger tasks (composition).
Example:
const john = { name: 'john', score: 10 };
const mary = { name: 'mary', score: 20 };
// `pipe` almost reads like a to-do list!
pipe(
getPlayerName,
getFirstName,
properCase,
addUserLabel,
createUserTemplate
)([john, mary]);
Surely the benefits are clear. FP code is more readable because we give can specific names to each custom combination of small functions. FP code is easier to debug because each small function is a distinct unit with one input and one output. FP code is maintainable because new tasks are usually recombinations of small functions already defined.
Implementation
Immutability with pure functions
In FP, we ensure that functions only change data inside themselves (immutability). We do so by using pure functions, those whose only consequence is returning the evaluated result, without changing data outside the function, i.e. no side effects. External data must be immutable, that is, external data must remain unchanged.
const num = 10; // data external to `add3` → should be immutable!
const add3 = (x) => {
num++; // altering `num` outside `add3` → big NO!
return x + 3;
};
add3(7);
To change data, you save it under a different name and change your copy, thus preserving the original data. Note that this is why map() returns a new array.
Composition with higher-order functions
With ordinary functions, we know we can generalize values to avoid repetition:
// repetition
const printHello = () => console.log('Hello');
const printHowdy = () => console.log('Howdy');
printHello();
printHowdy();
// generalization to avoid repetition
const printGreeting = (greeting) => console.log(greeting);
printGreeting('Hello');
printGreeting('Howdy');
So far we have been generalizing values, often strings or numbers.
But what if our functions are very similar except for a bit of functionality?
const copyArrayAndMultiplyBy2 = (array) => {
const output = [];
for (let i = 0; i < array.length; i++) {
output.push(array[i] * 2);
}
return output;
};
const copyArrayAndDivideBy2 = (array) => {
const output = [];
for (let i = 0; i < array.length; i++) {
output.push(array[i] / 2); // ← minimal variation to the above
}
return output;
};
copyArrayAndMultiplyBy2([1, 2, 3]); // → [2, 4, 6]
copyArrayAndDivideBy2([1, 2, 3]); // → [0.5, 1, 1.5]
This is repetitive. All the lines in the two functions, except for the name and the specific operation on the array element, are exactly identical. Remember, do not repeat yourself! So what can we do?
We can generalize * 2 and / 2 out of the two functions by passing in a function as an argument.
const copyArrayAndManipulate = (array, doSomething) => {
// new parameter, a function (callback)
const output = [];
for (let i = 0; i < array.length; i++) {
output.push(doSomething(array[i])); // new function in action
}
return output;
};
const multiplyBy2 = (input) => input * 2;
const divideBy2 = (input) => input / 2;
copyArrayAndManipulate([1, 2, 3], multiplyBy2); // → [2, 4, 6]
copyArrayAndManipulate([1, 2, 3], divideBy2); // → [0.5, 1, 1.5]
We are taking in an array and an operation, running that operation on each element of the array, and returning the resulting array. The array is generalized (we can pass in any array) and also the operation is generalized (we can pass in any function that fits).
Note then that we have ended up with two functions on our hands:
- The auxiliary function
doSomethingbeing passed in (the generalized operation), or callback, used by the main function. - The main function itself, known as a higher-order function, i.e. a function that takes in another function.
| Higher-order function | Callback |
|---|---|
| Main function, with a hole (blank) shaped for any function that fits. | Auxiliary function, passed in as a piece of the main function. |
You now have a higher-order function (HOF) that can be joined up with any operation that fits. Remember, the defining feature of a HOF is that is has a blank for functionality that is yet to be decided. The result is that HOFs allow you to create multiple unique functions by joining up (composing) little blocks of code together. This is possible because JavaScript functions can be used just as ordinary objects, so any function that fits can be passed in as an argument to the HOF.
map()
We just created a function that takes in a value (an array) and a generalized operation and returns a transformed version of that value (a new array, with a generalized operation applied to every element in it). An array went in, a transformation happened, and another array came out.
This function that takes in an array and another function and returns an array transformed by that other function, which we dubbed copyArrayAndManipulate(), is known in JavaScript simply as map(). It is a HOF stored in the prototype property of JavaScript's built-in Array object.
[1, 2, 3].map(multiplyBy2); // → [2, 4, 6]
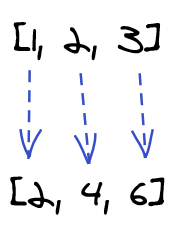
Let's now tweak this idea a bit.
The HOF map() acts on each element in the array in isolation: array element 1 at index 0 is transformed and the resulting 2 is placed in the array to be returned, without this transformation affecting the next array element 2 at index 1 or its resulting 4. The individual array elements are isolated from each other; the only relationship is between the pre- and post-transformation version of each element. Look at the diagram: one arrow per transformation.
But there is also another HOF that can act on each array element in sequence, that is, a HOF that acts on the first element, takes its result and uses it as an input to the next transformation.
reduce()
Take another look at our implementation of map(), previously called copyArrayAndManipulate():
const map = (array, doSomething) => {
const output = [];
for (let i = 0; i < array.length; i++) {
output.push(doSomething(array[i]));
}
return output;
};
On the first line in the body, we created a new empty array.
const output = [];
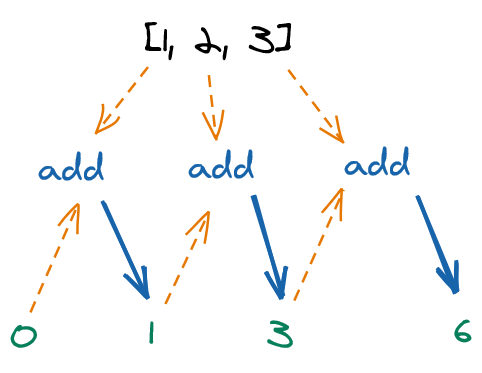
This empty array was then populated with values on each iteration the loop. To be specific, the very first iteration of the loop took the new empty array output, took also the number that resulted from evaluating doSomething(array[0]) and combined the array and the number into a single entity by pushing the number into the array.
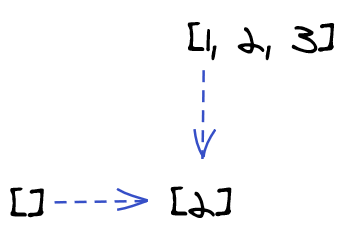
mapIn the loop inside map(), at the first iteration, two entities became one: the empty array [] and the result of the transformation 2 (two initial entities) became the single-element array [2] (one final entity).
What about the second iteration?
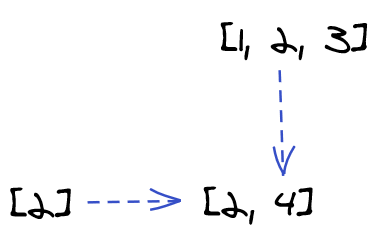
mapAgain, at the second iteration, two entities became one: the single-element array [2] and result of transformation 4 (two initial entities) became the two-element array [2, 4] (one final entity).
The takeaway here has become clear: pushing a value into an array is a reduction. Again, look at the reduction in the third iteration:
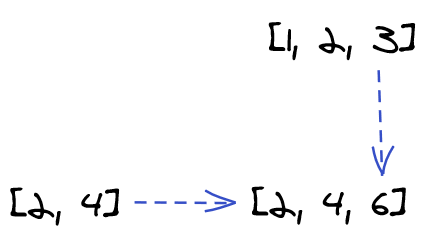
mapAt each of the three iterations we performed a combination of two entities into one, or a reduction. The first reduction received an original value (an empty array), while the second and third reductions received the result of the previous reduction (a single- and a two-element array) as one of its inputs.
The array went from being an input at the start of the first iteration...
- to an output at the end of the first iteration,
- to an input at the start of the second iteration,
- to an output at the end of the second iteration, and so on.
This array, which is successively accumulating changes as it becomes an input and an output at each iteration, is known as an accumulator. (Here it is an array, but it could have easily also been a number or a string.)
In turn, the rule by which we combine the accumulator and each element is called the reducer. Just as with map(), the reducer is the auxiliary function (callback) that is passed as an argument into the main function. Again, here the reducer was push(), but it could have easily also been any function that takes in two inputs and returns out one output. A reducer is what combines the accumulator and each element in an array in succession until a single final result is reached.
We said that any function that fits can be a reducer. So what about another example of a reducer? We can create a function that takes in an array and a combination rule and returns the condensed form of the array:
const takeArrayAndCondense = (array, combinationRule, buildingUp) => {
for (let i = 0; i < array.length; i++) {
buildingUp = combinationRule(buildingUp, array[i]);
}
return buildingUp;
};
const add = (a, b) => a + b;
const condensedFormOfArray = takeArrayAndCondense([1, 2, 3], add, 0);
Or with more formal variable names:
const reduce = (array, callback, accumulator) => {
for (let i = 0; i < array.length; i++) {
accumulator = callback(accumulator, array[i]);
}
return accumulator;
};
const add = (a, b) => a + b;
const result = reduce([1, 2, 3], add, 0);
We have thus implemented our very own version of the actual built-in reduce(), a higher-order function!
const add = (a + b) => a + b;
const result = [1, 2, 3].reduce(add, 0);
The only difference between our own version and the built-in implementation is that reduce() is a method of every array, a method stored in the array at Array.prototype, and so the built-in implementation only takes in two arguments: the reducer and the accumulator.
The reducer is the rule for how to combine the accumulator and each element of the array, whereas reduce() is the built-in higher-order function that takes in a reducer as well as an array and an accumulator.
But what was the practical purpose of understanding reduction and implementing reduce()? We will see soon enough!
filter()
Another higher-order function is filter(), which takes in a function (callback, i.e. a test returning true or false) and an array, runs that function on each item of the array, and returns a copy of the array containing only those elements for which the function returned true.
const myArray = [1, 2, 3, 4];
const greaterThan2 = (n) => n > 2;
myArray.filter(greaterThan2); // → `[3, 4]`
Chaining
Remember the concept: in FP, we combine functions into larger tasks (composition). Now that we are familiar with various HOFs, we can actually start to combine them through a process called chaining.
For example, we can combine functions using filter() and reduce():
const myArray = [1, 2, 3, 4];
const greaterThan2 = (n) => n > 2;
const add = (a, b) => a + b;
myArray.filter(greaterThan2).reduce(add, 0);
// result of reduction of filtered array: ´7´
// The above is the same as:
const filteredArray = myArray.filter(greaterThan2);
filteredArray.reduce(add, 0);
// result of reduction of filtered array: ´7´
This is known as chaining higher-order functions. The output array of the first HOF is the input array of the second HOF. Since arrays share methods via their __proto__ link to Array.prototype, you can simply use the dot notation to chain an array method to the array output of a higher-order function.
But note the precondition for chaining: chaining HOFs works only if the non-final HOF returns an array, e.g. map() or filter(). (As opposed to this, reduce() returns a primitive a number, while forEach() run its callback without returning anything at all.) This precondition is very limiting. How can we combine functions that do not return an array? That is, how do we combine functions when the "interface" between the output of one function and the input of the next do not match up?
Piping
A naïve solution to compose non-array-returning functions might be global variables:
const multiplyBy2 = (n) => n * 2;
const add3 = (n) => n + 3;
const divideBy5 = (n) => n / 5;
const initialResult = multiplyBy2(11);
const intermediateResult = add3(initialResult);
const finalResult = dividedBy5(intermediateResult);
console.log(finalResult); // → `5`
This is inelegant and risky. A clumsy attempt at fixing the naïve solution might be nesting the functions:
const multiplyBy2 = (n) => n * 2;
const add3 = (n) => n + 3;
const divideBy5 = (n) => n / 5;
const result = divideBy5(add3(multiplyBy2(11)));
This is unreadable and has inverted the logical order of operations! But, this clumsy attempt is hinting at the better solution: we are combining a function with a value to get a single evaluated result, only to immediately take that result and feed it into the next function, and so on. This is a series of reductions.
As you know, reduce() is used with an array of elements and an accumulator and a combination rule in order to produce a value that has been combined with each element in the array in sequence.
Now consider: reduce() can be used with an array of functions and an accumulator and a combination rule in order to produce a value that has been combined with (i.e., undergone) every function in the array in sequence.
const multiplyBy2 = (n) => n * 2;
const add3 = (n) => n + 3;
const divideBy5 = (n) => n / 5;
const reduce = (array, callback, accumulator) => {
for (let i = 0; i < array.length; i++) {
accumulator = callback(accumulator, array[i]);
}
return accumulator;
};
const runFunctionOnInput = (input, fn) => fn(input);
const result = reduce([multiplyBy2, add3, divideBy5], runFunctionOnInput, 11);
Only two things have changed from the previous reduce to this version:
- the previous version took in an array of numbers and a function as the rule for how to combine them,
- this version takes in an array of functions and a function as the rule for how to combine them.
The rule for how to combine them might look odd at first sight:
const runFunctionOnInput = (input, fn) => fn(input);
But runFunctionOnInput could not be more straightforward: if you provide an input and a function, the combination rule runFunctionOnInput will combine them, most naturally, by running the function on the input, which allows you to do this:
reduce([multiplyBy2, add3, divideBy5], runFunctionOnInput, 11);
Step by step:
- Take the initial accumulator
11and feed it intomultiplyBy2. - Run
multiplyBy2on11(per the combination rule), get back22and feed22intoadd3. - Run
add3on22(per the combination rule), get back25and feed25intodivideBy5. - Run
divideBy5on25(again, per the combination rule), get back5and you are done.
All the loop does is run the function array[i] on the accumulator and immediately update the accumulator with the result of running the function, so that the next function array[i + 1] is run on the updated accumulator, and so on until you have exhausted all the functions in the list.
In other words: Before, we were successively combining each number in the array with the accumulator by using any function we passed in. Now, we are successively combining each function in the array with the accumulator by always using a very simple rule: fn(acc), i.e. running every function in the list on the variable that is accumulating all the transformations.
Chaining allows you to compose certain HOFs, as long as the array-returning HOFs are run first. Reduction is the solution for composing any functions, as long as these receive and return the same number of arguments.
reduce() provides a nicely readable way of combining various functions:
reduce([multiplyBy2, add3, divideBy5], runFunctionOnInput, 11);
Note that there are no dots . as in chaining. This style is known as point-free coding. And from this, as you can see, there is one small step to the end goal, pipe:
pipe([multiplyBy2, add3, divideBy5])(11);
Advanced composition techniques
Function decoration
Remember: map() is a function that takes in an array and another function and returns an array transformed by that other function. map() contains blanks to be filled in with another function, i.e. map() is editable, which makes your code more composable.
map() is extremely useful, but it is also limited to transforming arrays. What if you want to edit a function that is not map()? How do we make a function, after it was created, contain blanks to be filled in with another function?
The answer is decoration. But to understand decoration, we need to review closures first, with an emphasis on how closures get to have memory.
Back to closures
Remember static or lexical scoping: Where you create your function, not where you call it, determines what data your function has access to. When a function is created, it takes with it (in its backpack!) all the data in needs to run wherever it is called. A closure grabs the data it needs to run even if it is found in its enclosing scope, that is, the scope where the function was first declared.
const createSpecial = () => {
let counter = 0; // `counter` is closed over
const incrementCounter = () => counter++;
return incrementCounter;
};
const mySpecial = createSpecial();
// `mySpecial` stores `() => counter++` together with
// its closed-over variable `counter`
mySpecial(); // `counter` updated to 1
mySpecial(); // `counter` updated to 2
incrementCounter is born in the scope of createSpecial and, naturally, incrementCounter needs access to the counter variable, which is not in its own scope, but in its enclosing scope. Therefore, counter is closed over by incrementCounter, i.e. counter can be read and updated by incrementCounter wherever incrementCounter is called. In short, the value of counter is persisted, so closures have memory.
Closures and immutability Closures persist data outside themselves, so they break the FP principle of immutability of state. On the other hand, data persistence enables the use of advanced composition techniques like partial application. There is a balance to be struck here. Remember that our goal is not rigid adherence to FP for the sake of it—our goal is to apply FP ideas to make code more readable, testable and maintainable.
Returning to decoration
Since closures have memory, we can feed our function into a closure in order to, for example, keep track of how many times our function has been called.
const oncify = (fn) => {
let counter = 0;
const oncifiedFunction = (input) => {
if (counter === 0) {
const result = fn(input);
counter++;
return result;
}
return 'Sorry!';
};
return oncifiedFunction; // brand new function with `counter` in its backpack!
};
const multiplyBy2 = (num) => num * 2;
const oncifiedMultiplyBy2 = oncify(multiplyBy2);
oncifiedMultiplyBy2(10); // → 20
oncifiedMultiplyBy2(2); // → "Sorry!"
Inside oncify, we create a function oncifiedFunction containing the blank fn, which is populated on creation when calling oncify, and we return that newly created function. Note that input inside the closure remains a blank, because input will be the future argument of the function you have just created and returned out.
Now, when you call oncify and provide it with arguments, you get that what was formerly known as oncifiedFunction but now operational, with the blank populated, and with the new name oncifiedMultiplyBy2. To make sure, you can log out oncifiedMultiplyBy2, you will see the function formerly known as oncifiedFunction with its blank populated.
(input) => {
if (counter === 0) {
const output = multiplyBy2(input);
// originally a blank, now populated with `multiplyBy2`
counter++;
return output;
}
oncify is a fun example of function decoration. What else can we achieve by decorating a function?
Partial application
Remember: Reduction, the basis of piping, is our solution for composing any functions as long as these receive and return the same number of arguments. In practice, this requires us to convert multi-argument functions into single-argument functions. The number of arguments in a function or arity (i.e. how many inputs) must match up with the number of outputs from the previous function. Aiming for a 1-to-1 interface is the easiest way to ensure this. Prevent arity mismatch or your piping will get clogged up!
But how do we prevent arity mismatch in a function? We can decorate it by "prefilling" an argument in the backpack of a closure.
const multiply = (a, b) => a * b; // arity of 2, problem found!
function prefill(fn, prefillValue) {
// `prefillValue` is closed over by `prefilledFunction`!
const prefilledFunction = (input) => fn(input, prefillValue);
// `fn` is the function being prefilled
// `prefillValue` is the value being applied to `prefilledFunction`
// `input` is the future argument that will be fed to the
// function being created
return prefilledFunction;
}
const multiplyBy2 = prefill(multiply, 2);
multiplyBy2(3); // arity of 1, problem solved!
Inside prefill, we create a function prefilledFunction containing the three blanks fn, input and prefillValue. Two of the blanks, fn and prefillValue, are populated on creation when calling prefill, and we return the function. Note that input inside the closure remains a blank, because input will be the future (single!) argument of the function you are creating.
When you call prefill and provide it with its two arguments, you get that what was formerly known as prefilledFunction but now operational, with its two blanks populated, and with the new name multiplyBy2. To make sure, you can log out multiplyBy2 and you will see the function formerly known as prefilledFunction with its two blanks populated.
(input) => multiply(input, 2);
// originally three blanks, now two populated with `multiply` and `2`
This is known as partial application: applying (think of it as welding, or permanently attaching) an argument onto a function to lower its arity, thus making it more composable.