Designing a URL shortener
2023-08-13T11:53:41.316ZDesigning a URL shortener
Shorthand links are everywhere. URL shorteners have gained in popularity over the years, from dedicated services like Bitly and TinyURL to in-app features in LinkedIn and Twitter. A URL shortener turns a long URL into a shorter one that redirects accordingly. Shorthand links are convenient - easy to read, write, and remember, and fitting for use cases like messaging apps that enforce brevity.
Shorthand links are also useful for:
-
Analytics: As an intermediary, a shortener can collect analytics on link clicks, user locations, URL access patterns, etc.
-
Customization: Some shorteners enable users to set the text of their links ("vanity URLs") for branding or readability.
-
Marketing: Shorteners are often used to mask affiliate links, containing parameters to track how users flow to a site.
Let's explore what it takes to design a simple URL shortener.
Creating IDs out of URLs
A URL shortener converts a user-submitted URL to an ID and appends it to a base URL, e.g. https://miniurl.com/<id>. So we are looking to map a long URL to an ID. To decide on a mapping strategy, let's walk backwards from the end result: the ID. How long should it be? One, five, ten characters? How do we decide?
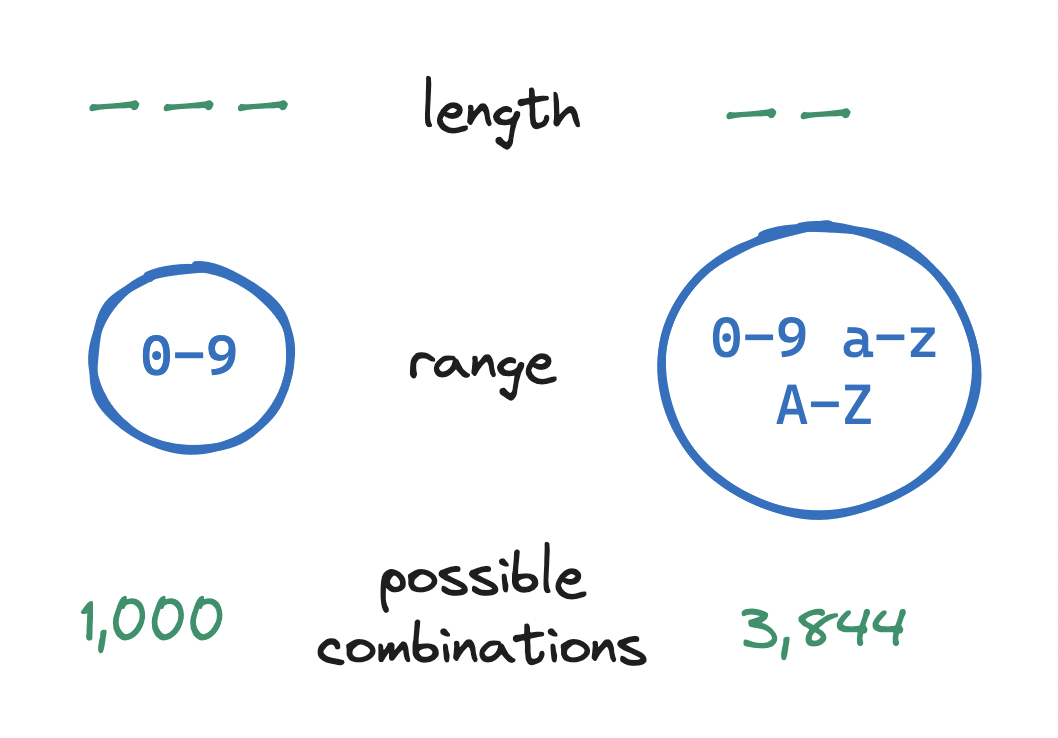
An ID is a string, and any string may be created from a range of available characters. For a string of a given length, the broader the range of characters allowed in the string, the higher the number of unique strings we can create.
For example, with a 3-character string drawing from the set 0-9 (10 characters), we can create 1,000 unique strings: 10^3. But with a 2-character string drawing from a set made up of 0-9 and A-Z and a-z (62 characters), we can create 3,844 combinations: 62^2. The range we may draw from is the base, and the string length is the exponent.
In our case, what is the range of available characters? A URL may contain...
-
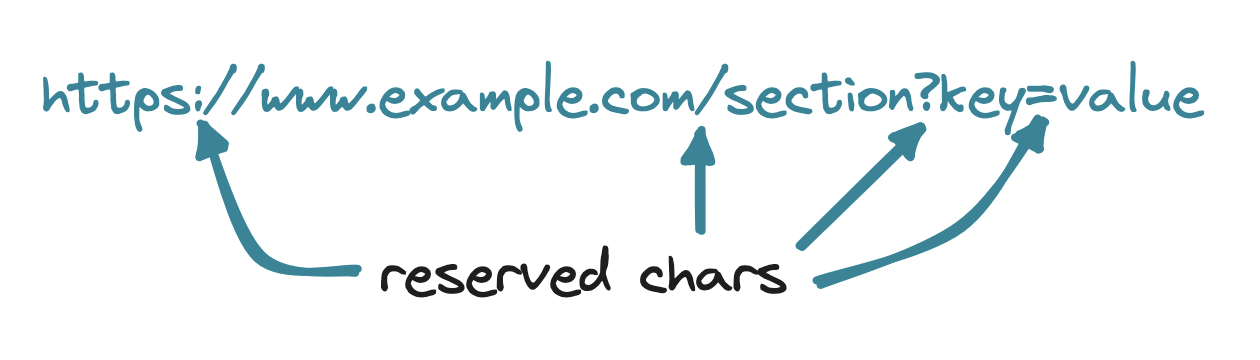
Unreserved characters: Those intended literally, with no special purpose in a URL. Namely, uppercase letters
A-Z, lowercase lettersa-z, digits0-9, minus-, underscore_, dot., and tilde~. -
Reserved characters: Those having a special purpose in a URL. We leave them unencoded when we'd like their special effect to apply, or encoded ("escaped") when we mean them literally. Reserved are the colon
:, slash/, ampersand&, question mark?, equals=, plus+, dollar$, comma,, at sign@, exclamation mark!, single quote', and brackets[]()<>, among others.
Hence, an unencoded # in https://example.com#footer sends the user to a section in a page. But when we mean # literally, we encode it by converting its ASCII number to hexadecimal and preprending the percent sign: %23. In the URL https://example.com?id=%23123 the query parameter ?id=%23123 contains the key id and the encoded value #123.
Since including reserved characters in our IDs means encoding them, i.e. growing them to three characters each, we have good reason to rule out reserved characters from our IDs. Plus, to keep the range strictly alphanumeric, we can also rule out the four unreserved non-alphanumeric characters -_.~.
Hence we are left with a range of 62 characters: 26 uppercase letters (A-Z), 26 lowercase letters (a-z), and 10 digits (0-9). How can we derive the length of the ID based on this range? In other words: How do we find the shortest length of an ID such that our range creates the desired number of IDs?
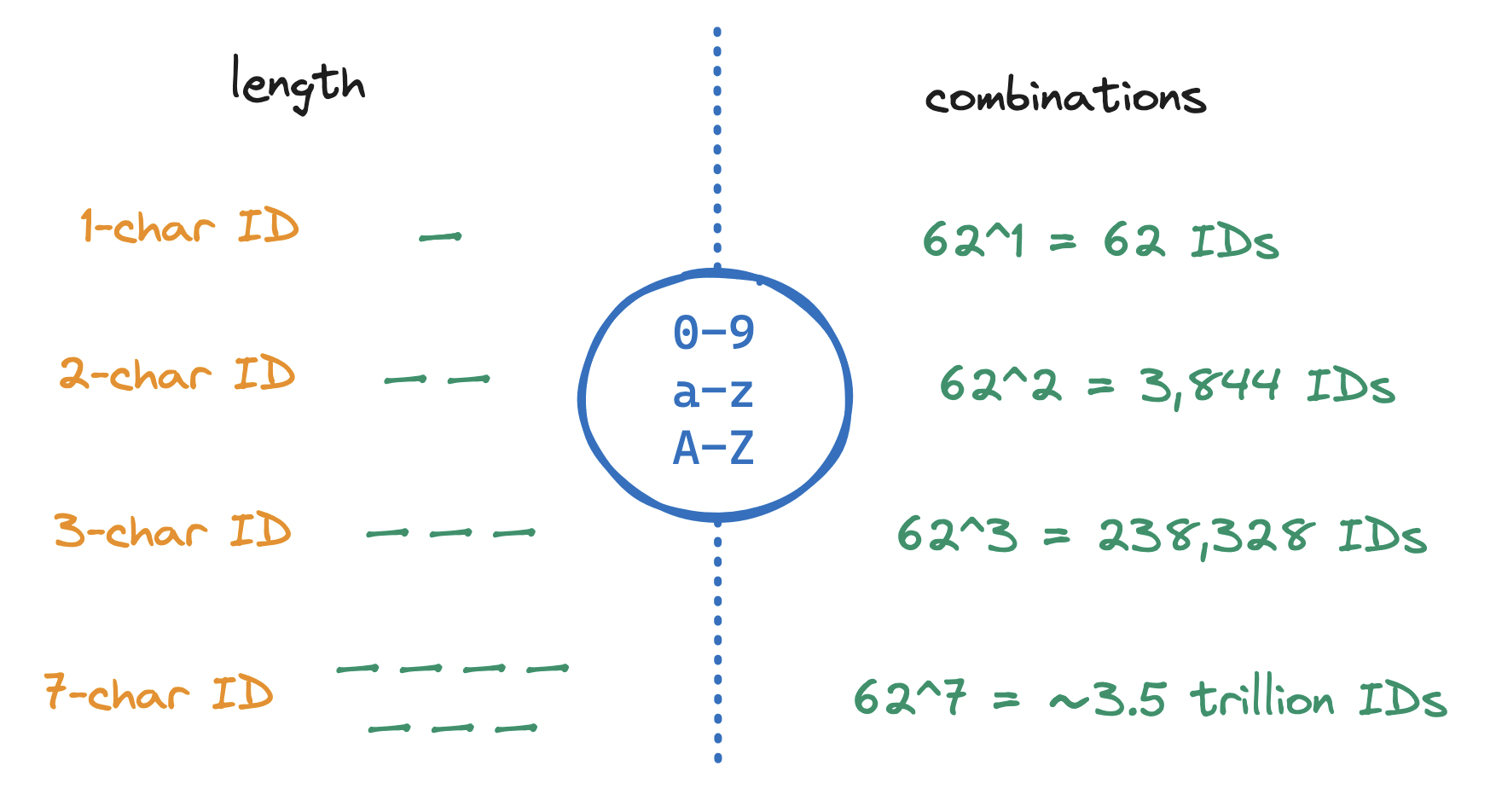
Range and length dictate the number of unique results. In our case, let's assume we are required to support up to 3 trillion IDs. Given this requirement, let’s settle on an ID of length 7, drawing from a range of 62 alphanumeric characters. This will afford us ~3.5 trillion IDs, enough to cover the 3 trillion requirement, plus some headroom for further growth.
Mapping URLs to IDs
We now know the exact shape of the end result. Let's keep walking backwards from it. How do we map long URLs into IDs of this shape? And importantly, how do we make sure the mapping is unique? Mapping two different URLs to the same ID would lead users to unintended locations.
The naivest approach would be to map long URLs to plain numeric IDs, e.g. https://en.wikipedia.org/wiki/Berlin#Galleries_and_museums becomes 123 which we use in https://miniurl.com/123. But, we need to support ~3.5 trillion IDs of length 7. If we create IDs by adding up a number from 0 to ~3.5 trillion, we will hit the 7-character limit at 9,999,999, a long way before the end of the range.
So plain numeric IDs are a non-starter. What about hashing? A hash function takes an input and produces an output ("hash value") of fixed length. The process is deterministic, so the same input always produces the same output, which prevents us from pointing separate URLs to the same ID. Or does it?
Let's hash a URL using several common hashing algorithms and look at the hash values:
Input: https://en.wikipedia.org/wiki/Berlin#Galleries_and_museums
SHA-256 (62 chars)
3558dd3a17f03db28e8cde27230ce5f356ce107dabc4f6ceb65a3c741863c771
MD5 (32 chars)
dd04013e2a94e7d0c9a4d7d5f8305e36
CRC-32 (8 chars)
1d24f671
These hash values are all hexadecimal, so they satisfy our 62-character range. But even the shortest one exceeds our max length of 7. (Writing a custom hashing algorithm that fits all these criteria would be exceedingly complex.) As a workaround, we could truncate the hash value to the first 7 characters, but we'd run the risk of creating duplicates. As another workaround, when storing a truncated hash, we could:
- first check whether we already have this ID in store,
- if so, append a random character to the ID,
- enter a loop where we recheck and re-append until the ID is unique, and
- only then store it.
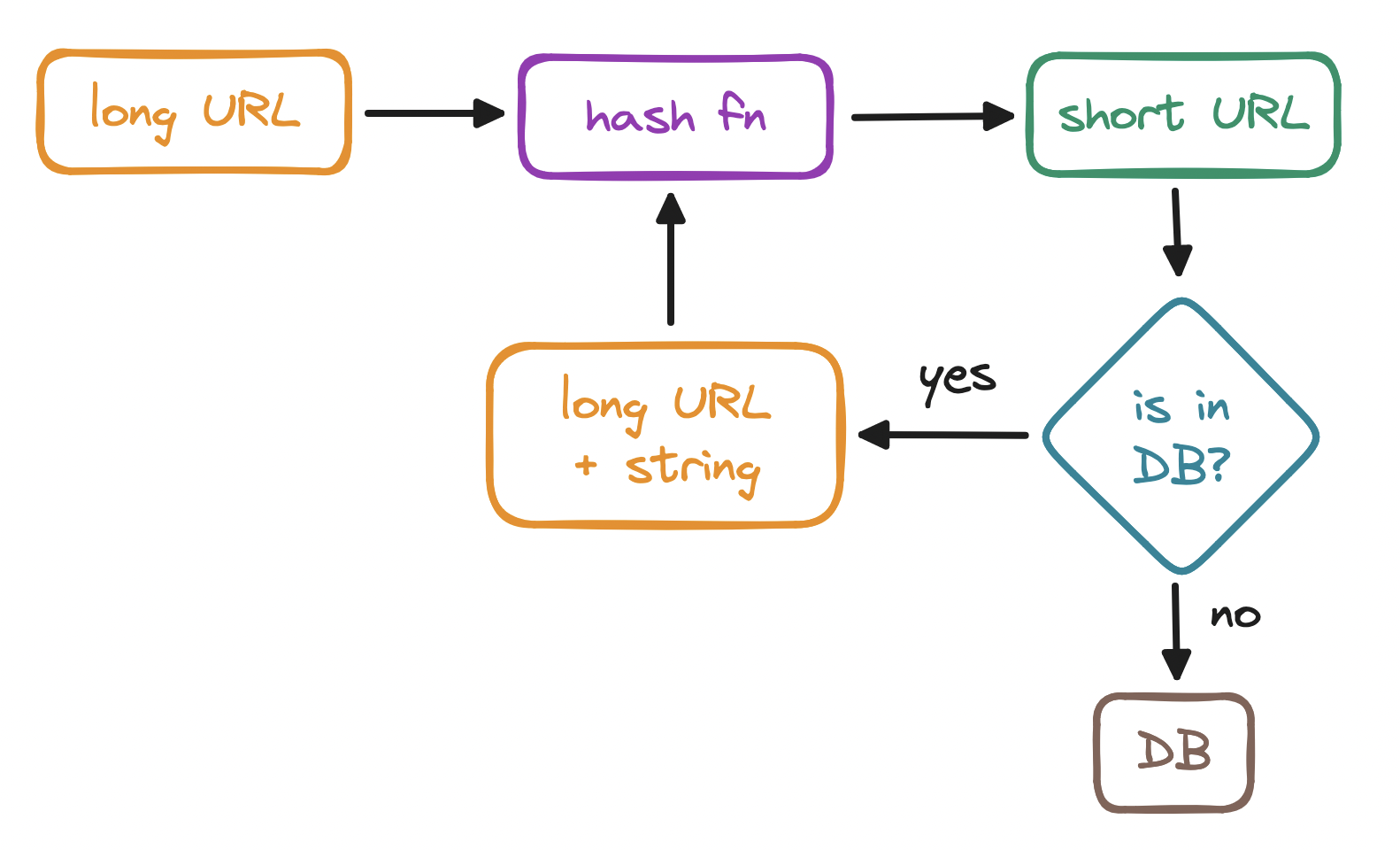
But, putting this much pressure on the DB on every write, plus indefinitely retrying and delaying the save operation, is far from ideal.
Let's backtrack. We know that integer IDs (base 10) quickly run out of space in our range. But, we also know that the higher the base, the more numbers we can represent with less space, since we have more symbols to work with. The number 1,000,000 in base 10 (7 characters) is f4240 in base 16 (5 characters).
Hex IDs hit the 7-character limit at 16^7 or ~268 million (base 10), still far from the end of the range, but closer than before. This points us in the right direction. Can we compress IDs by encoding them in a higher base? Can we find a high enough base?
We already did! The base number that raised to the power of 7 equals ~3.5 trillion is, as we calculated above, 62. Mapping a URL to an ID encoded in base 62 is a workable and often recommended solution.
But mind the tradeoffs:
- While the numbers 0 to ~3.5 trillion will not require more than 7 characters to be represented in base 62, these encoded values will be of variable length, which can make the IDs seem inconsistent.
- Even when encoded, IDs are predictable. A user can find out valid IDs that, depending on the requirements, they should have no knowledge of. This might be a security concern.
- Keeping track of an incrementing integer means keeping state, which means keeping ID generators in sync when scaling out the system.
Data modeling and storage estimates
With our IDs completed, let's model our data. At the very least, we must store the mappings from long URLs to encoded IDs. Can we think of other data that we might need to store for each ID? Depending on the use case, we might need to store:
- the creation date of the ID, to automatically clear old IDs,
- its last access date, to automatically clear unused IDs,
- its expiration date, for more granular control over the lifetime of IDs,
- the creator of the ID, to prevent abusive users from creating too many,
- how many times it has been accessed, to track URL usage patterns, and
- how many times the same ID has been created, also for analytics.
Moving forward, let's assume we need to store the mapping and its creation date, expiration date, last access date, and the ID of the user who created it. As our data model is simple with only one relation, we could choose to store records as rows in a SQL database or as documents in a NoSQL database.
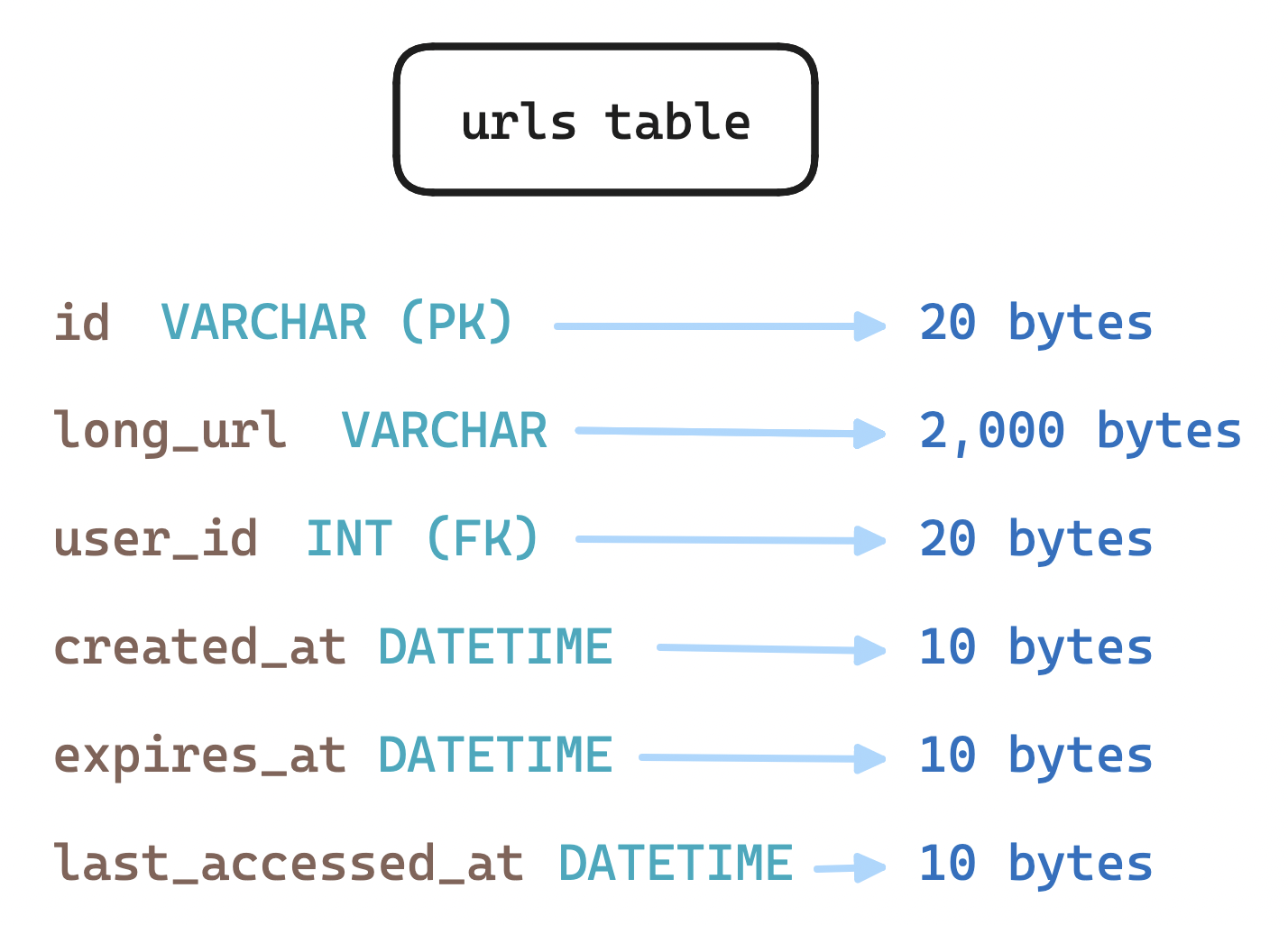
As for storage, if we expect 100 million daily active users, each creating one URL a day, and if these URLs must be persisted for five years, and if each record takes up around 2.5 KB, a rough total storage estimate would be:
2.5 KB * 100 million * 300 days * 5 years = 450 TB
Side note
Notice how we use 300 instead of 365 to simplify this back-of-the-envelope calculation.
URL shorteners tend to be read-heavy services, with a ratio of 100:1 reads to writes. At the stated 100 million URLs created per day, we'd need to support 10 billion reads per day. In terms of bandwidth, this translates to:
2.5 KB * 100 million * 10^(-5) seconds = 2.5 MB/s ingress traffic
2.5 KB * 10 billion * 10^(-5) seconds = 250 MB/s egress traffic
To optimize for reads, we would also benefit from caching the mappings in memory or in a Redis-like store. This would reduce the load on the database, while adding to the storage requirements.
Routing users via redirects
We have generated IDs, mapped long URLs to them, and stored the mappings. Finally, we need to lead users to their destinations. How do we route users?
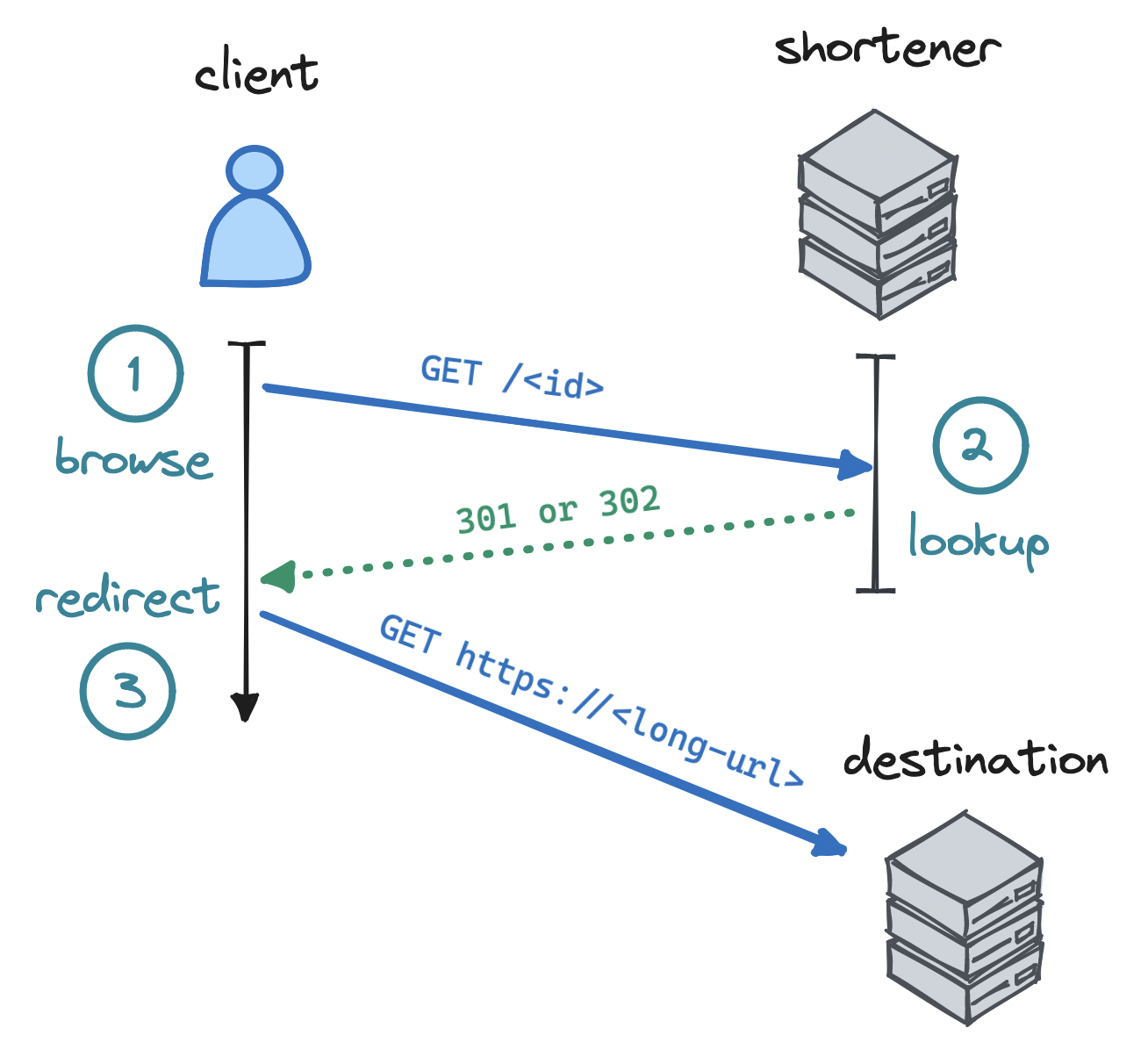
When a user creates a short URL, our client app sends a request to our server, e.g. at POST /api/v1/url/shorten, with a long URL in the payload body { "long_url": "..." }. The server receives this request, extracts the URL and generates a base62-encoded ID, e.g. 3idarWH, stores the mapping, and returns this ID to the client app. Our client app then adds the ID to our base URL and displays it to the user: https://miniurl.com/3idarWH
When a user clicks on this shorthand link, our service matches on the ID in the URL and requests the long URL, e.g. at GET /api/v1/urls/3idarWH. We receive the request, extract the ID, look up the original long URL, and send back a response. Finally, the HTTP headers in the response redirect the browser to the long URL:
Status code: <code>
Location: <long-url>
Which HTTP status code? Here we have a choice:
-
If we send back
301 Moved Permanently, the browser will cache the redirection, so future requests to the short URL will lead to the long URL directly, without going through our service. This reduces server load, but prevents us from collecting analytics. -
If we send back
302 Found (Moved Temporarily), the browser is less likely to cache the redirection, so future requests to the short URL are more likely to go through our URL shortener service. The tradeoff here is the opposite of the above.
For most users, the redirection in both cases will be nearly instantaneous.
Going further
In this article we have explored how to design a basic URL shortener: how to create IDs out of URLs, how to map URLs to IDs, how to store the mappings, and how to route users via redirects. But, this is only the very beginning of a design. URL shorteners are simple in concept, but they can be complex in practice.
To go further, consider:
- Rate limiting: How can we limit the number of URLs a user can create?
- Cleanup: How can we auto-delete old or unused URLs to keep the DB slim?
- Vanity URLs: How could we allow users to customize their short URLs?
- Analytics: How could we integrate the system with an analytics solution?
- Availability: How to scale the system's components to minimize downtime?
As we keep developing the system, we will have to keep an eye on functionality, performance, security, and maintainability. In doing so, monitoring and iteration will be key to operating a reliable URL-shortening service.