TypeScript and Set Theory
2022-04-15T15:07:33.331ZTypeScript and Set Theory
Presentation:
- Distributive Conditional Types - TypeScript Berlin Meetup #8
Introduction
Set theory is a branch of math devoted to sets, i.e. collections of elements. We can define a set either by enumerating the elements it contains:
Or by stating a rule to determine which elements belong in the set:
This notation is read "the set of all elements filter() function: it returns true if an item in the input belongs in the set that we are creating.
Once we have defined a set, we can describe the relation of a given element to the set. An element may, or may not, be member of (i.e., belong in) a set:
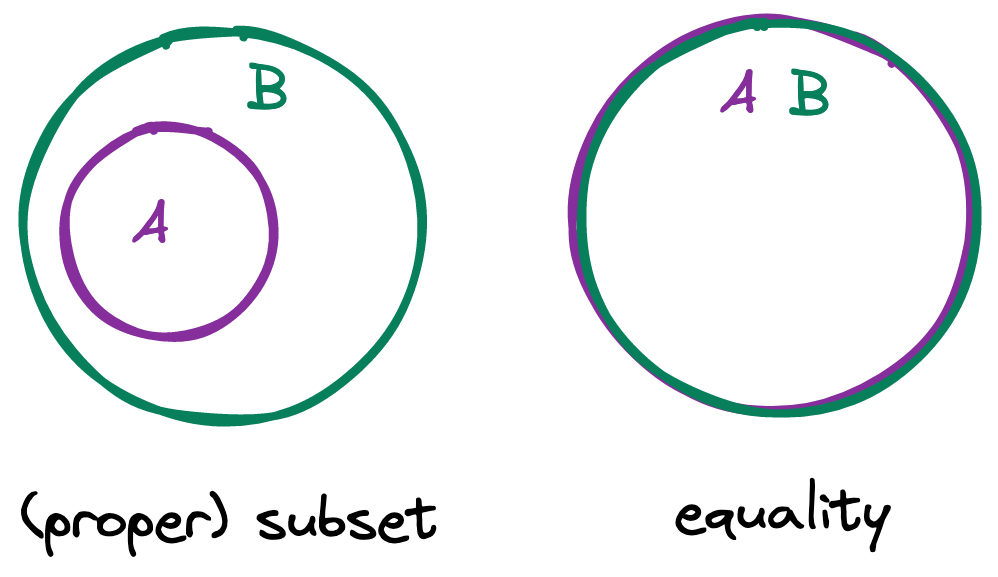
We can also describe the relation of a set to another set. A set is a subset of (i.e., contained in) another set if, and only if, every element of the first set is also an element of the second set. In other words, when all the items in one set exist in the other set, then the first is a subset of the second. Further, if there is also at least one element in the second set that does not exist in the first set, then the first (smaller) set is a proper subset of the second (larger) set, which is a superset of the first.
By implication, a set that is a subset of another set without being a proper subset of it may only be equal to that other set. A set equals another set if, and only if, every element of the former is a member of the latter and every element of the latter is a member of the former. Sets disregard order and duplicates — two sets are equal if, and only if, they contain the same elements.
Graphically:
By contrast, consider non-subsets. A set is not a subset of another set if there exists at least one element in the first set that is not a member of the second set — these are overlapping sets. And if no element in the first set is a member of the second set, then the sets are disjoint sets.
Graphically:
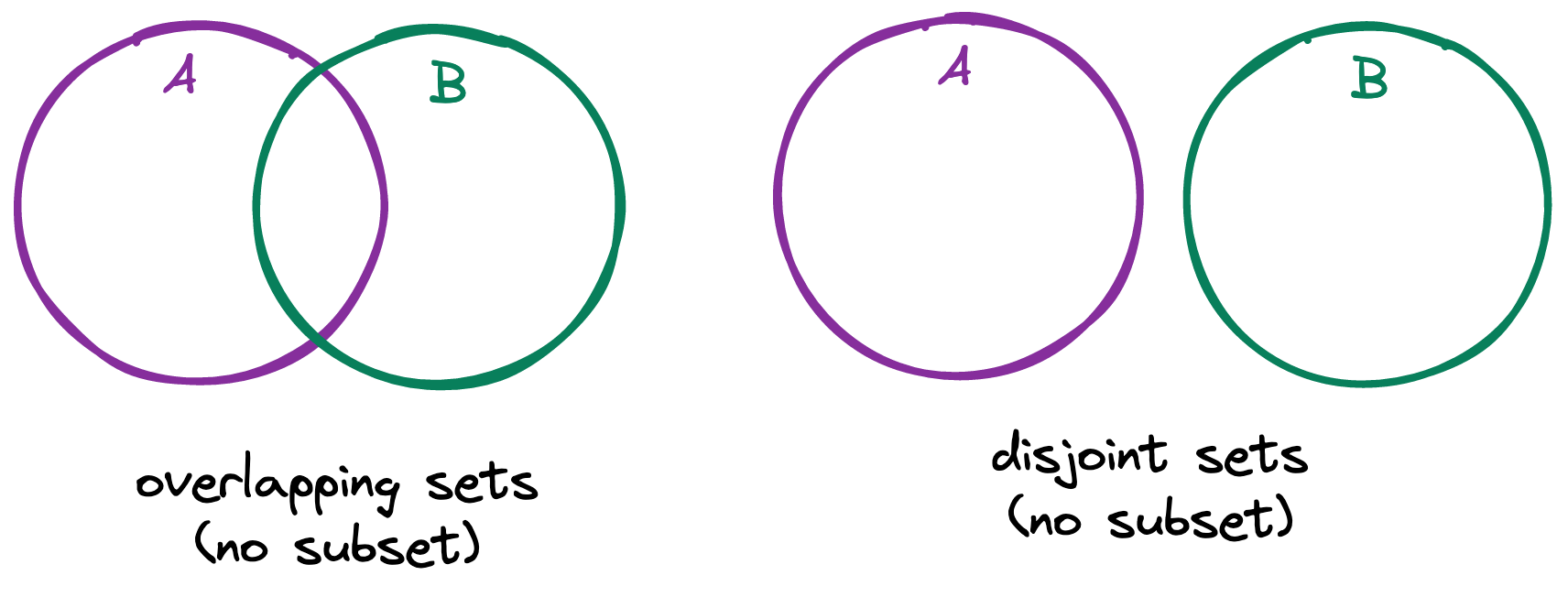
Finally, two special cases. The empty set, symbolized Ø, is the set that contains nothing, e.g. the set containing the elements in common between disjoint sets. To be precise, the empty set is not nothing — rather, it is a container of nothing.
And its opposite is the universal set, symbolized U, the set that every set is a subset of, and that every element is a member of. In math, the universal set delineates the boundary for discussion.
Further reading:
This is a brief lead-in for the next section. To discover more about set theory:
- Discrete Mathematics and its Applications (ch. 6) - Susanna S. Epp
- Essential Discrete Mathematics for Computer Science (ch. 5) - Harry Lewis and Rachel Zax
- Learning to Reason: An Introduction to Logic, Sets, and Relations (ch. 3) - Nancy Rodgers
Types as sets
Set theory offers a mental model for reasoning about types in TypeScript. Through the lens of set theory, we can view a type as a set of possible values, i.e. every value of a type can be thought of as an element in a set, which makes a type comparable to a collection whose elements belong to it based on the collection's definition.
Imagine...
- the
numbertype as the infinite set of every possible number, - the
stringtype as the infinite set of every possible character permutation, and - the
objecttype as the infinite set of every possible shape that an object can take — in JavaScript, objects include functions, arrays, dates, regular expressions, etc.
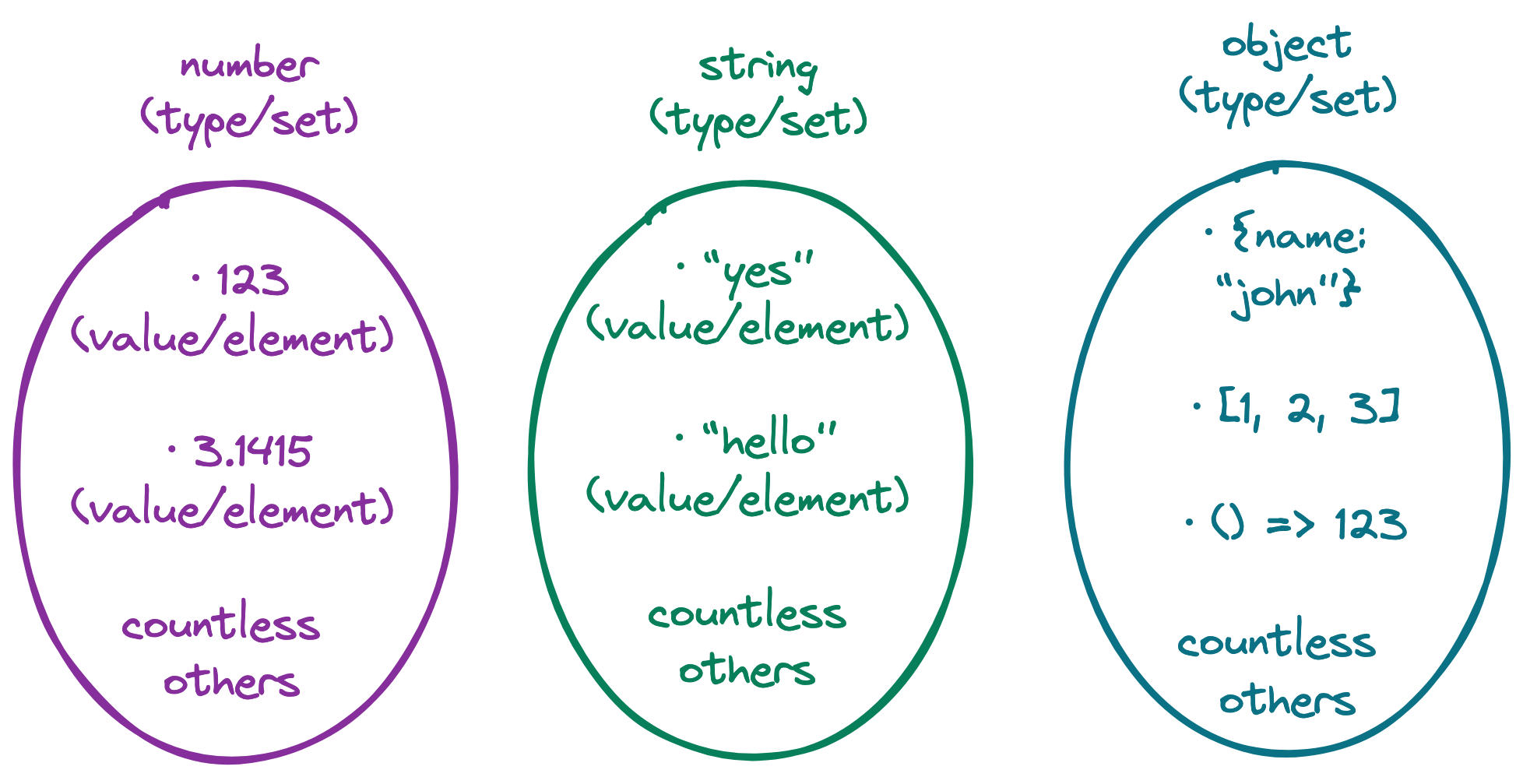
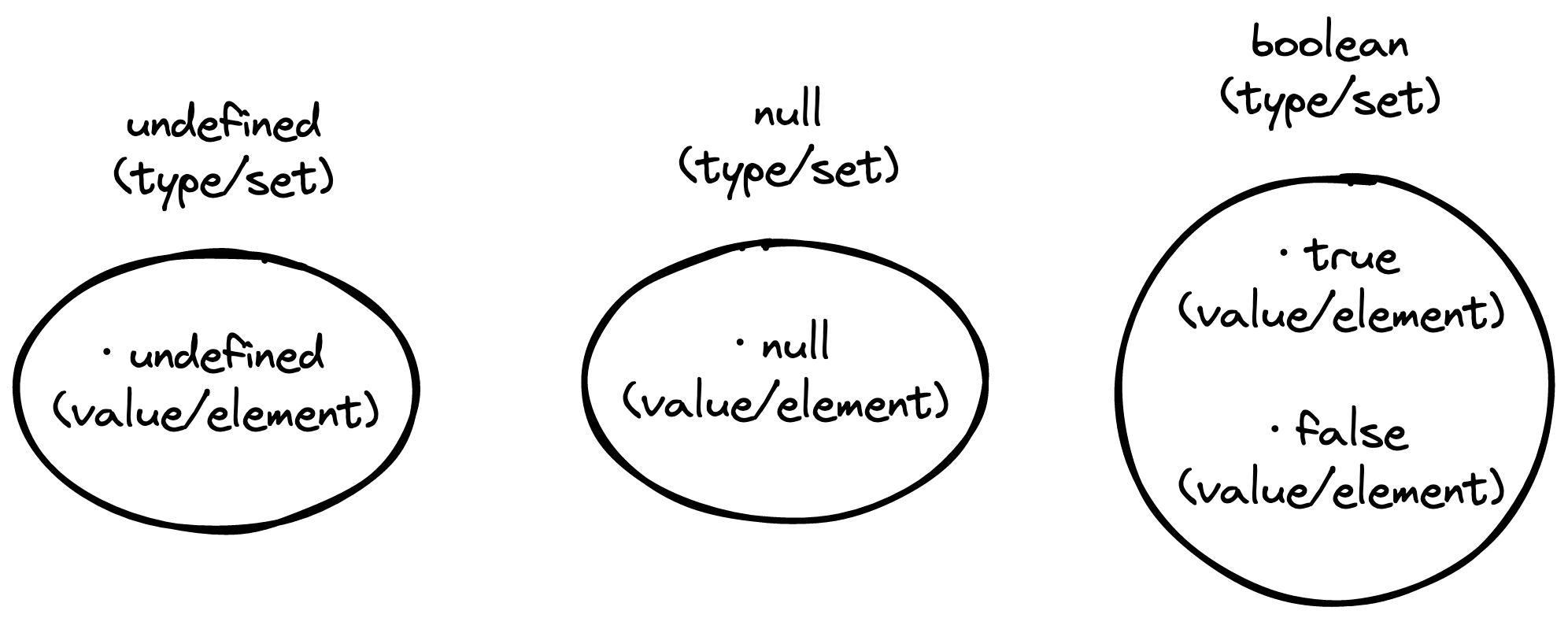
Not all types-as-sets are infinite. Consider the undefined, null, and boolean types, all of which are sets holding a limited number of elements.
Imagine...
- the
undefinedtype as the finite set containing the single valueundefined, - the
nulltype as the finite set containing the single valuenull, and - the
booleantype as the finite set containing the two valuestrueandfalse.
Other finite sets are the string literal type and the string literal union type — the first is a set that contains one user-specified string literal; the second is a set that contains a handful of user-specified string literals. Each of these sets is a proper subset of the set of all possible strings:
// both true, string literal ⊂ string
type W = 'a' extends string ? true : false;
type X = 'a' | 'b' extends string ? true : false;
// true, string literal ⊆ same string literal
type Y = 'a' extends 'a' ? true : false;
// true, string ⊆ string
type Z = string extends string ? true : false;
Notice how extends in a conditional type is TypeScript's equivalent for:
(proper subset, i.e. every element of A is in B, and B has extra elements). (subset, i.e. every element of A is in B, and B has no extra elements)
This also holds true for extends in a generic constraint:
// constraint: T ⊂ string or T ⊆ string
declare function myFunc<T extends string>(arg: T): T[];
And in interface declarations:
interface Person {
name: string;
}
interface Employee extends Person {
salary: number;
}
// true, Person ⊂ object
type Q = Person extends object ? true : false;
// true, Employee ⊂ Person
type R = Employee extends Person ? true : false;
Since object is the set of all possible object shapes, and since an interface is the set of all possible object shapes whose properties match the interface, any given interface is a proper subset of the object type.
And in turn, when a child interface extends a parent interface, the child interface is the set of all possible object shapes whose properties match the parent interface. A child interface is thus a proper subset of a parent interface, which is itself a proper subset of the object type.
Notice also that, if a type is a proper subset of another, their relation hints at their compatibility on assignment:
let myString: string = 'myString';
let myStringLiteral: 'only' | 'specific' | 'strings' = 'only';
// both assignable, string ⊂ string, string literal ⊂ string
myString = 'myNewString';
myString = myStringLiteral;
// not assignable, string ⊄ string literal
myStringLiteral = myString;
These and other compiler behaviors are explained by set theory.
Thinking of types as sets can help us reason about:
- Type compatibility during assignments.
- Type creation with type operators.
- Conditional type resolution.
Part 1: Assignability
An assignment stores a value in a specific memory location labeled with a variable. Both the value and the variable are typed, and so assignability (i.e., assignment compatibility) depends on two types: that of the value being assigned and that of the recipient variable.
When the two types are identical, the assignment succeeds:
let a: number;
a = 123; // succeeds, number is assignable to number
But when the two types are not identical, for the assignment to succeed, a type transformation must occur. When we assign a value of a type to a variable of different type, we are type-casting, that is, we are causing the type of the value to become another type in the variable.
Type-casting often takes the form of upcasting: we broaden the type of the value into a more encompassing type in the variable, e.g. a string literal becomes a string.
let myString: string = 'myString';
let myStringLiteral: 'only' | 'specific' | 'strings' = 'only';
myString = myStringLiteral; // upcasting succeeds, assignable
Upcasting transforms a subtype into a supertype, that is, a proper subset into a superset. TypeScript allows this transformation because it is type-safe: if a set is a proper subset of another, then any element in the smaller set is also a member in the larger set.
On the other hand, downcasting is normally disallowed. To ensure type safety, we cannot declare that a member of a larger set is also a member of a smaller set — we cannot know this for certain. And if both sets are equal, the two types are identical and so there is no need for type-casting.
Reversing the assignment above shows that downcasting a string into a string literal is disallowed:
let myString: string = 'myString';
let myStringLiteral: 'only' | 'specific' | 'strings' = 'only';
myStringLiteral = myString; // downcasting fails, not assignable
Following this logic, we can predict which type transformations will be allowed during assignments, except for two special cases.
Assignability-wise, never is special in that...
neveris assignable to every other type, and- no type is assignable to
never.
This means that every type can be on the receiving end of never, and never itself cannot be on the receiving end of any other type. In other words, upcasting from never to any other type is possible (albeit see the boxed comment below), whereas downcasting from never to anything else is disallowed for type safety. never is thus called the bottom type, symbolized ⊥ in type theory.
In set theory terms, never is the set that no element can ever be a member of, and that no other set can ever be a subset of — never is the empty set, the set that refuses to contain anything.
const a: never = 1; // downcasting fails, not assignable
No example for valid never assignment:
never can always be broadened to a more encompassing type, but in practice, no example can be provided for never being assigned to another type because, by definition, a value of type never cannot ever happen — no actual value of type never should ever be available for assignment.
But if in practice a never value is unavailable for assignment, what does it mean for never to be assignable to another type? Refer to this answer.
The opposite case is unknown, mostly used to type a value whose type is meant to be confirmed before usage, e.g. JSON.parse() should ideally return unknown. TypeScript forces us to find out what type every unknown value is before we may safely use it.
let a: unknown;
a.toUpperCase(); // still unknown, disallowed
if (typeof a === 'string') {
a.toUpperCase(); // narrowed to string, allowed
}
Assignability-wise, unknown is special in that...
- every type is assignable to
unknown, and unknownis not assignable to any other type.
unknown can be on the receiving end of every type, and no type can be on the receiving end of unknown. In other words, upcasting from any other type to unknown is possible (albeit rarely useful, since unknown exists to require the caller to type-check the value), and downcasting from unknown is disallowed for type safety.
Since unknown is meant to be type-checked ("refined") before use, unknown is potentially every type: every type is under the umbrella of unknown. Hence unknown is called the top type, symbolized ⊤ in type theory.
let x: unknown = 'a'; // upcasting succeeds, assignable
let a: unknown;
const b: string = a; // downcasting fails, not assignable
In set theory terms, unknown is a superset of all other types — it is the set that every element is a member of, and that every set is a subset of. unknown is therefore the universal set, the set that contains everything.
In sum, never and unknown resemble other types in that downcasting is disallowed, but differ from other types in that upcasting from never, and upcasting to unknown, are both possible but in practice rarely happen.
any as an escape hatch
Oddly, any is a mixture of never and unknown. any is assignable to every type, just like never, and every type is assignable to any, just like unknown. As a blend of two opposites, any has no equivalent in set theory, and is best seen as an escape hatch to disable TypeScript's assignability rules.
Part 2: Type creation
We can use set operators to combine existing sets into a new set:
- The union of A and B is the set of all elements that are in at least A or B.
- The intersection of A and B is the set of all elements that are both in A and in B.
- The difference of A minus B is the set of all elements that are in A and not in B.
- The complement of A is the set of all elements in U that are not in A.
Graphically:
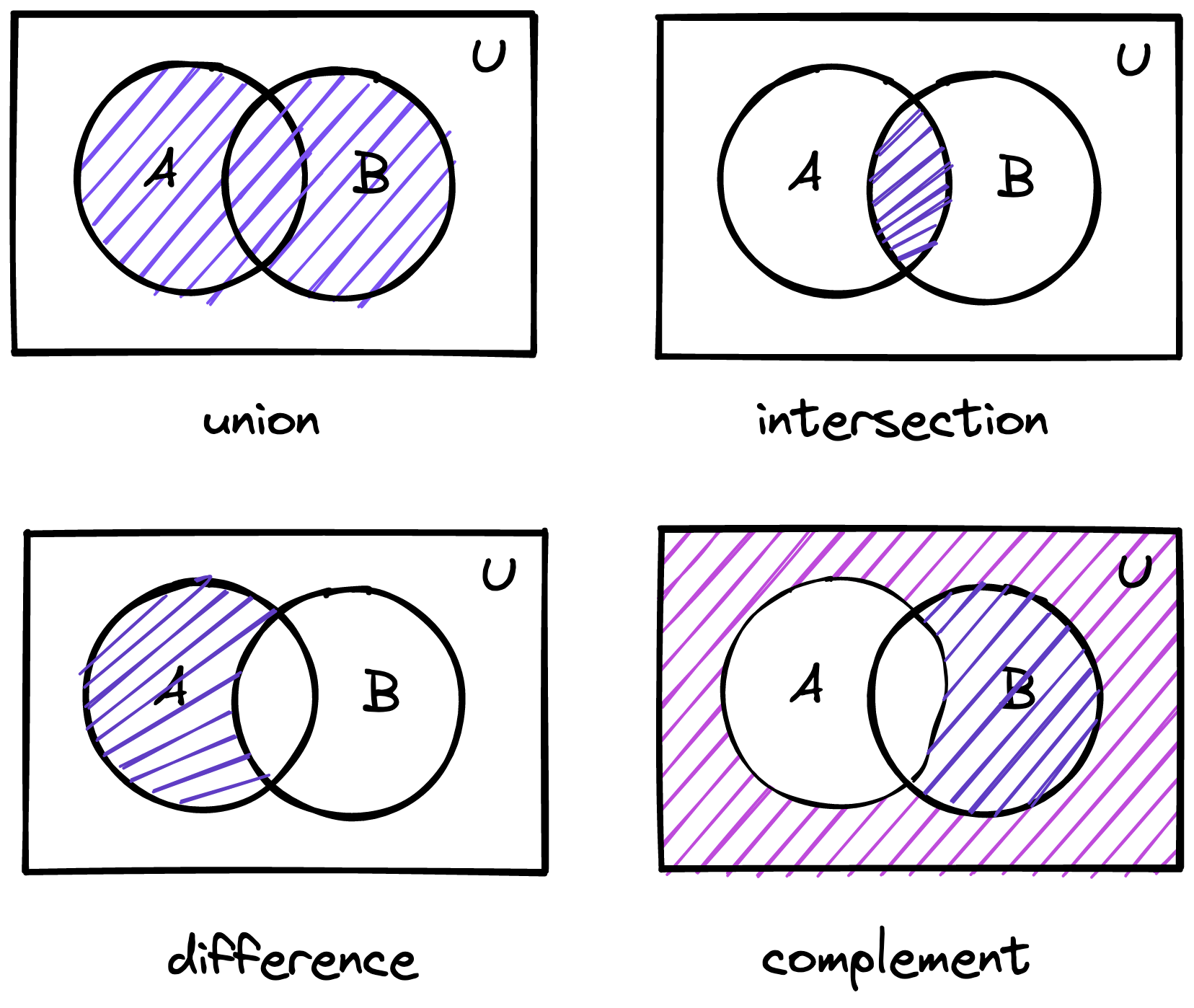
Out of these four set operators, TypeScript implements two as type operators:
|for union, and&for intersection.
Unionizing with | means creating a broader, more inclusive type made up of both input types, whereas intersecting with & means creating a smaller, more restrictive type made up of only the elements shared by both input types.
As type operators, | and & operate on types (sets), not on the elements (values) that belong in those sets. Think of type operators as functions that take in types as inputs, and return another type as the output.
When operating on primitives, | and & behave predictably:
type StringOrNumber = string | number;
// string | number → both string and number are admissible
type StringAndNumber = string & number;
// never → no type is ever admissible
But when operating on interfaces, | and & seem to behave counter-intuitively.
Consider this example:
interface ICat {
eat(): void;
meow(): void;
}
interface IDog {
eat(): void;
bark(): void;
}
declare function Pet(): ICat | IDog;
const pet = new Pet();
pet.eat(); // succeeds
pet.meow(); // fails
pet.bark(); // fails
The | in a union type is usually taken to mean "either A or B is admissible". This roughly matches up with the fact that the boolean operator || means OR in an expression. Thinking of unions of interfaces in terms of OR, however, can be misleading.
Parsing the output type ICat | IDog as allowing "either the methods of ICat or the methods of IDog" leads us to believe that the output type ICat | IDog will accept an object with either the methods of ICat or the methods of IDog, but that is not what the compiler allows. Unionizing two interfaces produces a larger set, i.e. an interface with fewer methods - only those in common between the input sets. In other words, the union ICat | IDog is a new output set made up of the shared elements of its input sets.
And the converse holds true for intersections: & in an intersection type is usually taken to mean "one and the other". This matches up with the fact that the boolean operator && means AND in an expression. But thinking of intersections of interfaces in terms of AND can also be misleading.
Consider this example:
interface ICat {
eat(): void;
meow(): void;
}
interface IDog {
eat(): void;
bark(): void;
}
declare function Pet(): ICat & IDog;
const pet = new Pet();
pet.eat(); // succeeds
pet.meow(); // succeeds
pet.bark(); // succeeds
Intersecting two interfaces produces a smaller set, i.e. an interface with more methods - all methods in both input sets.
To sum up, when unionizing interfaces, thinking in terms of OR can cloud our interpretation, while visualizing a broader output set can help clarify it. And when intersecting interfaces, thinking in terms of AND can also cloud our interpretation, while visualizing a narrower output set can help clarify it.
But why are our expectations reversed when unionizing and intersecting interfaces?
The object type is the infinite set of all possible object shapes; an interface is the infinite set of all possible object shapes that have specific properties. An interface is then a subset of the object set. From the universe of all possible object shapes, those object shapes whose properties match the interface are assignable to it.
let a: object;
a = { z: 1 }; // { z: number } is assignable to object
Since an interface describes the shape of an object, the more properties we add to the interface, the fewer object shapes will match, and so the smaller the set of possible values becomes. Adding properties to an interface shrinks the set that it stands for, and vice versa.
interface Person {
name: string;
age: number;
isMarried: boolean;
}
When unionizing two interfaces, visualize two fully shaded sets that are partly overlapping. When we unionize, we are creating an output type that accepts types that match...
- one input type, or
- the other input type, or
- both.
From the universe of all possible object shapes, those three object shapes are assignable to the output type, which makes for an output type that is broader, more inclusive, than the two inputs by themselves. Thinking of unionizing interfaces with OR only makes sense when we remember to account for the overlap of both.
interface A {
a: 1;
}
interface B {
b: 1;
}
const x: A | B = { a: 1 }; // succeeds
const y: A | B = { b: 1 }; // succeeds
const z: A | B = { a: 1, b: 1 }; // succeeds, assignable to overlap
A union of primitives like string | number also produces an overlap, but there is no primitive that is simultaneously of two types, so there is nothing that can be assigned to an overlap of primitives. Since we tend to overlook this case, we default to thinking that the boolean OR is a precise way of thinking about unions of all types, which can lead us astray when operating on non-primitives.
And conversely, when intersecting two interfaces, visualize two partly overlapping sets, shaded only in their overlap. When intersecting, we are creating an output type that accepts only types that match the overlap, that is, only the shared segment.
interface A {
a: 1;
}
interface B {
b: 1;
}
const x: A & B = { a: 1 }; // fails
const y: A & B = { b: 1 }; // fails
const z: A & B = { a: 1, b: 1 }; // succeeds
An intersection of primitives like string & number always produces never, because no primitive can ever share elements with another. But interfaces are subsets of object, so an intersection of interfaces always produces an interface that can satisfy both input object shapes simultaneously. Even if the intersected interfaces have no properties in common, they share the commonality of being slices of all possible object shapes.
And again, carrying our intuition of intersecting primitives over to intersecting non-primitives causes us to think in boolean AND terms, and so we risk assuming, incorrectly, that x and y above should succeed when they do not.
Cumulative effect:
When we unionize different interfaces, the overlap accumulates properties. When we intersect different interfaces, the output type accumulates properties. When we declare that an interface extends another, the child interface accumulates properties.
In all three cases, this cumulative effect resembles that of interface declaration merging, where separate declarations of the same interface create an aggregate interface that accumulates the properties in each.
Part 3: Resolution of conditional types
In set theory, there are equations that hold universally true for all elements in a set.
In total, there are twelve laws for all four operators supported by sets — but since TypeScript implements only | and &, only some of all twelve laws apply to both sets and types. Of these, two pairs of laws are especially useful for making sense of conditional types: identity laws and idempotent laws.
A set in union with the empty set resolves to itself; a set in intersection with the universal set also resolves to itself. The special sets, just like their TypeScript equivalents, are collapsed by the identity laws:
type A = string | never; // resolves to string
type B = string & unknown; // resolves to string
A set in union with itself resolves to itself; a set in intersection with itself also resolves to itself. The duplicates, whether sets or types, are filtered out by the idempotent laws:
type A = string | string; // resolves to string
type B = string & string; // resolves to string
How do identity laws and idempotent laws relate to conditional types?
If a type is a set, then the condition in a conditional type amounts to a subset check. Is a set a (proper) subset of another? If so, then the given type is assignable to the recipient type. As the focus of the check, this given type we are asking about is called the checked type.
type R = 'a' extends string ? true : false; // true
type S = 'a' | 'b' extends number ? true : false; // false
type T = { a: 1; b: 2 } extends { a: 1 } ? true : false; // true
type U = { a: 1 } extends { a: 1; b: 2 } ? true : false; // false
If the checked type is concrete, conditional type resolution is straightforward. But what if the checked type is generic? When we introduce a generic into a conditional type, we usually do so in order to be able to access the generic in the resolved type, often to filter the input and/or transform the output:
type X<T> = T extends OtherType ? T : never;
type Y<T> = T extends OtherType ? T[] : never;
type Z<T> = T extends OtherType ? { a: T } : never;
It is when we pass a union type into a checked generic that conditional type resolution stops being straightforward and becomes open to interpretation.
When we pass a union to a generic in a conditional type, do we mean...?
- Check if each constituent of the union is a (proper) subset of the other type and resolve each type. Aggregate all resolved types in a union.
- Check if the union as a whole, meaning as a single set, is a (proper) subset of the other type and resolve the type.
The first interpretation is a distributive conditional type. Here, the check is distributed over each constituent of the union. This means that a question is asked of each union constituent, and a type is resolved based on the answer for each union constituent. This is TypeScript's default resolution strategy for a conditional type having a checked generic to which a union is passed.
// distributive conditional type
type ToArrayDist<T> = T extends unknown ? T[] : never;
// call to distributive conditonal type
type R = ToArrayDist<string | number>; // string[] | number[]
// distribution spelled out
type R =
| (string extends unknown ? string[] : never)
| (number extends unknown ? number[] : never);
// after checks performed and types resolved - end result
type R = string[] | number[];
Mind the difference:
A distributive conditional type distributes a check over a union, producing one resolved type per union constituent. Therefore, a distributive conditional type is unrelated to set distributive laws, which redistribute intersections and unions for three different sets, as shown at the start of this section.
The second interpretation, operating on the union as a whole, is a non-distributive conditional type. Since distributivity is the default behavior, disabling distributivity requires wrapping each of the two types in the condition with square brackets. Non-distributivity is TypeScript's alternative resolution strategy for a conditional type having a checked generic to which a union is passed.
// non-distributive conditional type
type ToArrayNonDist<T> = [T] extends [unknown] ? T[] : never;
// call to non-distributive conditional type
type R = ToArrayNonDist<string | number>;
// after single check performed and single type resolved - end result
type R = (string | number)[];
In the examples above, the conditions are always true (i.e., the false branches are never reached) so that we can focus on the distributive effect. Other ways of achieving an always-true condition are T extends any and T extends T. These always-true conditions are useful for creating distributive helpers:
// distributive conditional type
type GetKeys<T> = T extends T ? keyof T : never;
// call to distributive conditional type
type R = GetKeys<{ a: 1; b: 2 } | { c: 3 }>;
// distribution spelled out
type R
| { a: 1; b: 2 } extends { a: 1; b: 2 } ? keyof { a: 1; b: 2 } : never
| { c: 3 } extends { c: 3 } ? keyof { c: 3 } : never;
// after checks performed and types resolved
type R = keyof { a: 1; b: 2 } | keyof { c: 3 };
// after keyof operator applied - end result
type R = 'a' | 'b' | 'c';
By contrast, in distributive conditional types where true and false branches are both reachable, the resolution of each constituent is bound to turn up duplicate types and instances of never chained together in the output union. When duplicate types and instances of never occur, TypeScript applies identity and idempotent laws to filter and collapse the union of resolved types into its minimal expression:
// distributive conditional type
type NonNullable<T> = T extends null | undefined ? never : T;
// call to distributive conditional type
type R = NonNullable<string | string | string[] | null | undefined>;
// distribution spelled out
type R =
| (string extends null | undefined ? never : string)
| (string extends null | undefined ? never : string)
| (string[] extends null | undefined ? never : string[])
| (null extends null | undefined ? never : null)
| (undefined extends null | undefined ? never : undefined);
// after checks performed and types resolved
type R = string | string | string[] | never | never;
// idempotent laws removed unionized nevers
type R = string | string | string[];
// identity laws removed unionized duplicates - end result
type R = string | string[];
Finally, be aware that for a conditional type to trigger distributivity, the checked generic must be by itself to the left of extends, that is, not passed into another generic or otherwise altered during the check.
// distributive, checked generic by itself
type R<T> = T extends OtherType ? true : false;
// non-distributive, checked generic not by itself
type R<T> = SomeType<T> extends OtherType ? true : false;